
Come creare tabelle in un database NoSQL
Pubblicato: 2022-11-23In NoSQL, i dati vengono archiviati in coppie chiave-valore, documenti, colonne o oggetti. Lo scopo principale dell'utilizzo di un database NoSQL è la scalabilità e la flessibilità. Quindi, come si creano tabelle in un database NoSQL? Esistono alcuni modi per creare tabelle in un database NoSQL. Il modo più comune è utilizzare un archivio di valori-chiave, che è un tipo di database NoSQL. In un archivio chiave-valore, ogni pezzo di dati viene archiviato come coppia chiave-valore. La chiave viene utilizzata per identificare i dati e il valore sono i dati effettivi. Un altro modo per creare tabelle in un database NoSQL consiste nell'utilizzare un archivio di documenti. Un archivio di documenti è un tipo di database NoSQL che memorizza i dati nei documenti. Ogni documento è una raccolta di coppie chiave-valore. La chiave viene utilizzata per identificare il documento e il valore è il documento effettivo. Infine, puoi anche creare tabelle in un database NoSQL utilizzando un archivio oggetti. Un archivio oggetti è un tipo di database NoSQL che memorizza i dati negli oggetti. Ogni oggetto è una raccolta di coppie chiave-valore. La chiave viene utilizzata per identificare l'oggetto e il valore è l'oggetto effettivo.
I database NoSQL sono estremamente versatili e adattabili. In questo articolo impareremo come creare ed eseguire query su database Oracle e Amazon DB NoSQL. A causa dello stato di Amazon DB come archivio di valori-chiave, utilizza le chiavi per soddisfare le richieste di query. È anche relativamente semplice iniziare da zero grazie a questo metodo. I database Oracle NoSQL sono progettati per applicazioni ad alte prestazioni e traffico elevato. Big Data e Fusion Middleware, ad esempio, sono esempi di prodotti Oracle che lo incorporano. La creazione di un database in questo ambiente è un po' più complicata, se non altro perché manca la stessa interfaccia di AmazonDB.
Se vuoi creare una tabella, devi utilizzare il metodo NoSQLClient#tableDDL. È uno strumento potente che può essere utilizzato sia dai data scientist che dagli analisti. Per creare una query, utilizzare il metodo NoSQLClient#define. Promise of QueryResult è un array di oggetti Javascript che restituisce un risultato. I linguaggi di query del database tendono ad essere molto ricchi, quindi puoi padroneggiarli.
Nosql può avere tabelle?
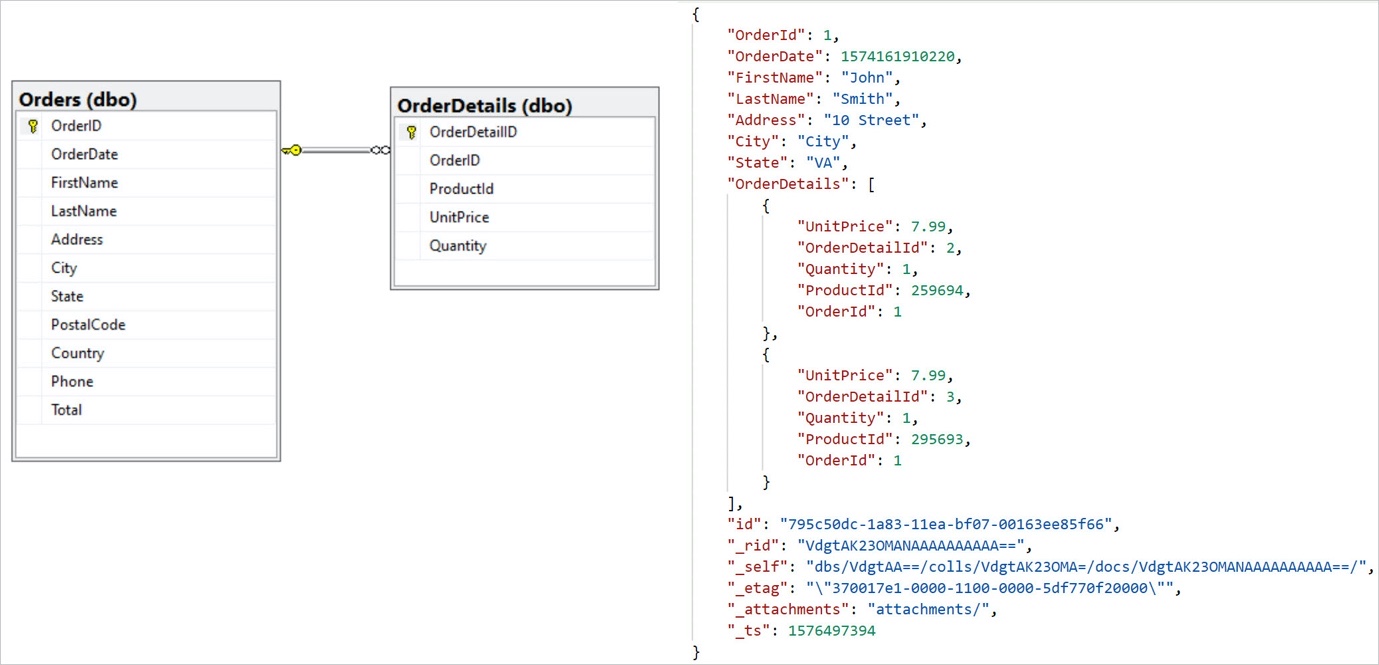
La struttura di un documento può essere la stessa o può essere di tipo diverso. Database SQL: i dati nei database NoSQL possono essere archiviati in tabelle con righe e colonne simili a RDBMS, ma il nome e il formato delle colonne variano da riga a riga. Un database a colonne larghe visualizza colonne di dati correlate tra loro.
NoSQL è stata nominata la prossima grande novità nell'architettura di sistema nel 2011. Molti database NoSQL hanno versioni diverse: alcuni hanno persino tabelle. I dati non possono essere correlati, poiché sono tutti d'accordo. Puoi usare SQL anche in un database NoSQL. È vero che NoSQL e SQL sono compatibili in vari modi. Di conseguenza, è meno probabile che NoSQL si traduca in atomicità, coerenza, isolamento o durabilità rispetto ai framework tradizionali. Una giurisdizione attendibile può inviare alcuni dati a una giurisdizione non attendibile in cambio di una piccola quantità di dati, se non del tutto, come risultato dello Sharding dei dati.
Quando utilizzi i database NoSQL, partizioni i dati su più macchine utilizzando lo sharding, assicurandoti che i dati corretti siano nel posto giusto quando ne hai bisogno. I dati possono essere archiviati in questi sistemi per molto tempo perché non cambiano molto o cambiano drasticamente nel tempo. Poiché i dati sono solo un singolo file, è possibile copiare facilmente i backup da altri server sulla rete. Sebbene un database tradizionale fornisca i vincoli, la coerenza e le protezioni necessari, esistono ancora molte applicazioni che richiedono queste caratteristiche. La novità promessa dai database NoSQL è svanita nel tempo nel tradizionale mondo dei database relazionali. Effettuare la transizione dai database relazionali a quelli NoSQL è una vera impresa e scegliere il provider e il gestore giusti può essere difficile. Questi database sono molto richiesti per le grandi aziende che necessitano del tipo di velocità fornita da NoSQL e gli esperti NoSQL sono molto richiesti. È possibile ottenere un buon stipendio se si aiuta il database di un'altra persona a eseguire database No relazionali o No non relazionali .
Questo metodo consente di accedere rapidamente e facilmente ai dati richiesti senza dover esaminare l'intera tabella. Questo metodo è particolarmente utile quando è necessario individuare rapidamente un dato specifico. Uno dei vantaggi dei database a colonne è la loro elevata velocità. Poiché leggono e scrivono dati più velocemente dei database relazionali, diventano ancora più veloci.
Come vengono chiamate le tabelle in Nosql?

Non esiste una risposta definitiva a questa domanda poiché diversi database Nosql possono avere convenzioni di denominazione diverse per le loro tabelle. Tuttavia, è generalmente accettato che le tabelle nei database Nosql siano generalmente chiamate "raccolte".

I database SQL, d'altra parte, sono tabulari e gestiscono l'archiviazione dei dati in modo diverso rispetto ai database NoSQL. Tra le caratteristiche principali di NoSQL ci sono il design semplice, il ridimensionamento orizzontale continuo e il controllo granulare della disponibilità. Nonostante il fatto che NoSQL offra numerosi vantaggi, ci sono anche alcuni svantaggi. Per applicazioni come la gestione delle transazioni, un database tradizionale è un'opzione migliore rispetto a un database basato su cloud. Nonostante il fatto che i database relazionali siano ancora utilizzati in una varietà di funzioni aziendali, i database NoSQL stanno guadagnando popolarità. I database NoQL sono ora utilizzati dalle aziende di vari settori verticali per gestire le loro applicazioni cloud, web e big data in tempo reale. È possibile implementare un'architettura peer-to-peer senza server con nodi coerenti nelle soluzioni NoSQL.
La nuova versione ha migliorato le prestazioni, consentendo tempi di lettura e scrittura più rapidi e una disponibilità continua dei dati. Un database NoSQL può essere un sistema a cinque livelli, ognuno dei quali ha il proprio insieme di vantaggi e svantaggi. Nonostante non esistano tipi di database "ideali", le aziende dovrebbero sceglierli in base alle loro esigenze aziendali. In sostanza, le coppie chiave-valore in NoSQL si riferiscono a tabelle hash che utilizzano una chiave univoca come puntatore a un elemento di dati specifico. Dynamo, Redis, Riak, Tokyo Cabinet/Tyrant, Voldemort, Amazon SimpleDB e Oracle BDB sono solo alcuni esempi di database NoSQL. I database NoSQL basati su colonne funzionano in modo simile ai database basati su colonne in quanto ogni colonna viene trattata separatamente. Questi database vengono utilizzati principalmente per business intelligence, data warehouse, cataloghi di schede di biblioteche e CRM, tra le altre cose.
Un database NoSQL è multilivello e ha un modello grafico come struttura primaria. Durante l'archiviazione, le relazioni dei nodi vengono archiviate come bordi, mentre le relazioni dei nodi vengono archiviate come nodi. Le relazioni si formano rapidamente qui a causa del set di dati esistente. Le applicazioni che traggono vantaggio da questo tipo di database includono i social network e l'analisi dei dati spaziali. MongoDB orientato ai documenti è un database NoSQL con schemi dinamici in grado di archiviare file. L'indicizzazione, la trasformazione e la combinazione dei documenti è possibile con il formato di scambio dati JSON di CouchDB e JavaScript viene utilizzato per indicizzare, trasformare e combinare i documenti. Il database Oracle NoSQL supporta i modelli di dati di tabella valore-chiave e JSON oltre ai modelli di dati di tabella valore-chiave e JSON.
È progettato per essere eseguito on-premise o nel cloud. InfiniteGraph è un database grafico molto specializzato che contiene dati grafici basati su modello. È basato sul cloud, scalabile e in grado di gestire dati ad alto throughput a tutti i livelli, inclusa la piattaforma stessa. Il linguaggio di query è progettato per gestire grafi complessi e query basate su valori. Sanità, telecomunicazioni, sicurezza informatica, finanza, produzione e networking sono le applicazioni più comuni di questa soluzione.
A differenza dei dati strutturati, lo storage senza schema consente un modello di dati più flessibile e agile per l'analisi. Poiché i dati non possono essere normalizzati, un database di ricerca ha un valore inferiore per la definizione dello schema. I file di documento possono essere utilizzati per generare query che aggregano i dati in documenti specifici. Una piattaforma di archiviazione basata su cloud come Azure Table può essere usata per archiviare dati strutturati non relazionali. Poiché è privo di schema, puoi facilmente adattare i tuoi dati per soddisfare le esigenze della tua applicazione man mano che diventa più complessa. Inoltre, i database di ricerca NoSQL sono progettati per l'analisi su dati semi-strutturati, mentre l'archiviazione tabella fornisce un approccio più flessibile e agile all'analisi dei dati su dati semi-strutturati.
Tre modi per organizzare i dati in un cluster
Cassandra organizza i dati in tabelle che vengono replicate tra cluster di nodi e i dati sono organizzati in modo tale da essere facilmente leggibili. Ogni tabella Cassandra è contraddistinta da uno schema, che definisce le colonne e i tipi di dati che possono essere utilizzati nella tabella. Le tabelle sono in genere organizzate in cluster, con ogni istanza che gestisce un sottoinsieme dello spazio tabella totale. HBase organizza i dati in base alla posizione fisica e li archivia in tabelle che si trovano fisicamente in cluster. Lo schema definisce le colonne e i tipi di dati che possono essere archiviati in una tabella, con le colonne e i tipi di dati corrispondenti. Nelle istanze HBase, le tabelle sono in genere organizzate in regioni e ogni istanza serve un sottoinsieme dell'intero tablespace. In un cluster Hypertable, i dati sono organizzati in tabelle che sono archiviate fisicamente sui nodi del cluster. Le tabelle sono in genere organizzate in frammenti, con ogni istanza che gestisce un sottoinsieme dello spazio tabella totale.