
NoSQL データベースでテーブルを作成する方法
公開: 2022-11-23NoSQL では、データはキーと値のペア、ドキュメント、列、またはオブジェクトに格納されます。 NoSQL データベースを使用する主な目的は、スケーラビリティと柔軟性です。 では、NoSQL データベースでテーブルを作成するにはどうすればよいでしょうか。 NoSQL データベースでテーブルを作成する方法はいくつかあります。 最も一般的な方法は、NoSQL データベースの一種であるキー値ストアを使用することです。 キーと値のストアでは、各データがキーと値のペアとして格納されます。 キーはデータを識別するために使用され、値は実際のデータです。 NoSQL データベースでテーブルを作成するもう 1 つの方法は、ドキュメント ストアを使用することです。 ドキュメント ストアは、ドキュメントにデータを格納するタイプの NoSQL データベースです。 各ドキュメントは、キーと値のペアのコレクションです。 キーはドキュメントを識別するために使用され、値は実際のドキュメントです。 最後に、オブジェクト ストアを使用して NoSQL データベースにテーブルを作成することもできます。 オブジェクト ストアは、データをオブジェクトに格納するタイプの NoSQL データベースです。 各オブジェクトは、キーと値のペアのコレクションです。 キーはオブジェクトを識別するために使用され、値は実際のオブジェクトです。
NoSQL データベースは非常に用途が広く、適応性があります。 この記事では、Oracle および Amazon DB NoSQL データベースを作成してクエリを実行する方法を学習します。 キー値ストアとしての Amazon DB のステータスにより、キーを使用してクエリ要求を実行します。 この方法のおかげで、最初から始めるのも比較的簡単です。 Oracle NoSQL データベースは、高性能でトラフィックの多いアプリケーション向けに設計されています。 たとえば、Big Data や Fusion Middleware は、それを組み込んだ Oracle 製品の例です。 この環境でのデータベースの作成は、AmazonDB と同じインターフェイスがないという理由だけで、もう少し複雑です。
テーブルを作成する場合は、NoSQLClient#tableDDL メソッドを使用する必要があります。 これは、データ サイエンティストとアナリストの両方が使用できる強力なツールです。 クエリを作成するには、NoSQLClient#define メソッドを使用します。 QueryResult の Promise は、結果を返す Javascript オブジェクトの配列です。 データベース クエリ言語は非常に豊富な傾向があるため、習得することができます。
Nosqlはテーブルを持つことができますか?
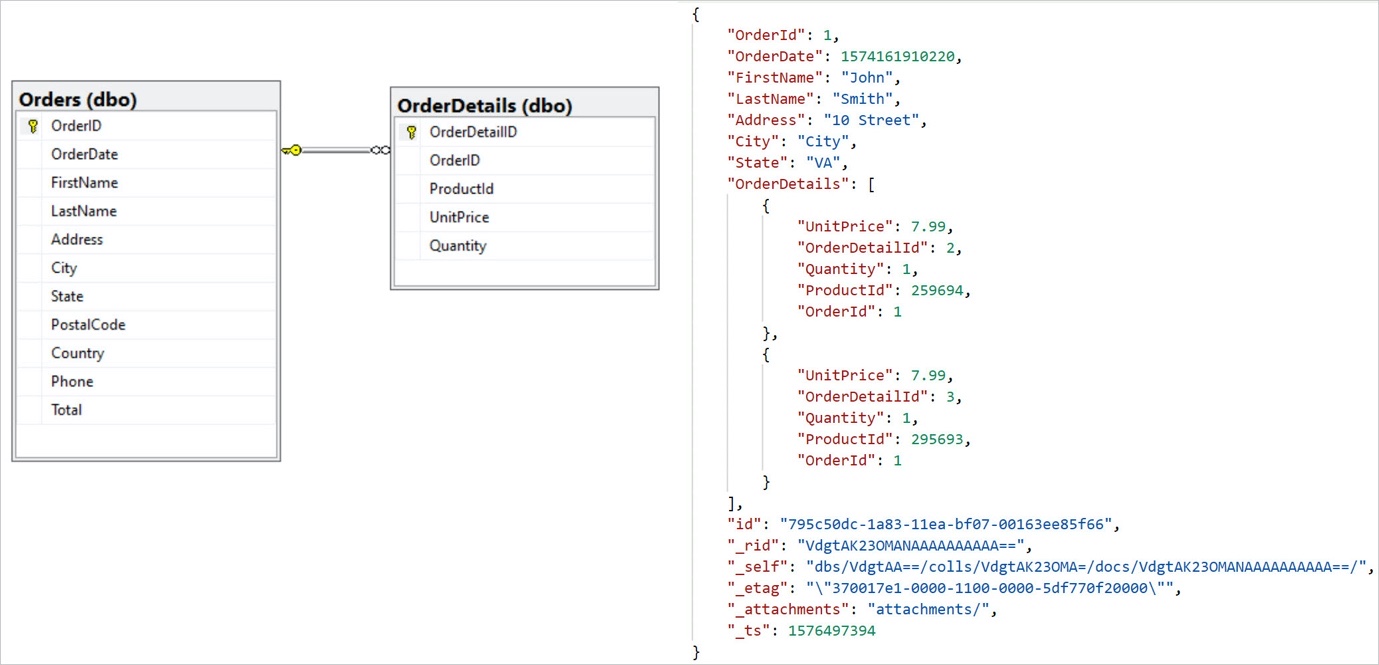
ドキュメントの構造は、同じにすることも、異なるタイプにすることもできます。 データベース SQL: NoSQL データベースのデータは、RDBMS と同様の行と列を持つテーブルに格納できますが、列の名前と形式は行ごとに異なります。 幅の広い列のデータベースには、相互に関連するデータ列が表示されます。
NoSQL は、2011 年にシステム アーキテクチャの次なる大物と名付けられました。多くの NoSQL データベースにはさまざまな特徴があり、中にはテーブルを持っているものもあります。 それらはすべて一致しているため、データを関連付けることはできません。 NoSQL データベースでも SQL を使用できます。 NoSQL と SQL がさまざまな点で互換性があることは事実です。 その結果、NoSQL は、従来のフレームワークよりも原子性、一貫性、分離、または耐久性をもたらす可能性が低くなります。 信頼できる管轄区域は、データのシャーディングの結果として、データがあったとしても少量のデータと引き換えに、一部のデータを信頼できない管轄区域に送信できます。
NoSQL データベースを使用する場合は、シャーディングを使用して複数のマシンにデータを分割し、必要なときに正しいデータが適切な場所に配置されるようにします。 これらのシステムは、時間の経過とともにあまり変化しないか大幅に変化するため、データを長期間保存できます。 データは 1 つのファイルのみであるため、ネットワーク上の他のサーバーから簡単にバックアップをコピーできます。 従来のデータベースは、必要な制約、一貫性、および保護機能を備えていますが、これらの特性を必要とするアプリケーションはまだ多くあります。 NoSQL データベースが約束した目新しさは、従来のリレーショナル データベースの世界では時間の経過とともに薄れてきました。 リレーショナル データベースから NoSQL データベースへの移行は実際の作業であり、適切なプロバイダーとマネージャーを選択するのは難しい場合があります。 これらのデータベースは、NoSQL が提供する種類の速度を必要とする大企業に高い需要があり、NoSQL の専門家の需要も高いです。 他の人のデータベースがリレーショナル データベースまたは非リレーショナルデータベースを実行するのを手伝うことができれば、かなりの給料を得ることができます。
この方法を使用すると、テーブル全体をふるいにかけることなく、必要なデータにすばやく簡単にアクセスできます。 この方法は、特定のデータをすばやく見つける必要がある場合に特に便利です。 カラム型データベースの利点の 1 つは、高速であることです。 データの読み取りと書き込みがリレーショナル データベースよりも高速であるため、さらに高速になります。
Nosql で呼び出されるテーブルとは何ですか?

Nosql データベースごとにテーブルの命名規則が異なる場合があるため、この質問に対する明確な答えはありません。 ただし、Nosql データベースのテーブルは通常「コレクション」と呼ばれることが一般的に認められています。

一方、SQL データベースは表形式であり、NoSQL データベースとは異なる方法でデータ ストレージを処理します。 NoSQL の主な機能には、シンプルな設計、シームレスな水平方向のスケーリング、きめ細かい可用性の制御などがあります。 NoSQL には多くの利点がありますが、いくつかの欠点もあります。 トランザクション管理などのアプリケーションでは、クラウドベースのデータベースよりも従来のデータベースの方が適しています。 リレーショナル データベースは依然としてさまざまなビジネス機能で使用されているにもかかわらず、NoSQL データベースの人気が高まっています。 NoQL データベースは現在、リアルタイムのクラウド、Web、およびビッグデータ アプリケーションを処理するために、さまざまな業種の企業で使用されています。 NoSQL ソリューションで一貫したノードを使用して、サーバーレスのピアツーピア アーキテクチャを実装することができます。
新しいバージョンではパフォーマンスが改善され、読み取りと書き込みの時間が短縮され、データの継続的な可用性が実現されています。 NoSQL データベースは 5 層システムにすることができ、それぞれに独自の利点と欠点があります。 「理想的な」データベースの種類はありませんが、企業はビジネス要件に基づいてデータベースを選択する必要があります。 基本的に、NoSQL のキーと値のペアは、一意のキーを特定のデータ項目へのポインターとして使用するハッシュ テーブルを参照します。 Dynamo、Redis、Riak、Tokyo Cabinet/Tyrant、Voldemort、Amazon SimpleDB、および Oracle BDB は、NoSQL データベースのほんの一例です。 列ベースの NoSQL データベースは、各列が個別に処理されるという点で、列ベースのデータベースと同様に機能します。 これらのデータベースは、主にビジネス インテリジェンス、データ ウェアハウス、図書館カード カタログ、CRM などに使用されます。
NoSQL データベースはマルチレベルであり、主要な構造としてグラフ モデルがあります。 保存中、ノードの関係はエッジとして保存されますが、ノードの関係はノードとして保存されます。 ここでは、既存のデータ セットにより、関係が迅速に形成されます。 このタイプのデータベースから恩恵を受けるアプリケーションには、ソーシャル ネットワークや空間データ分析が含まれます。 ドキュメント指向の MongoDB は、ファイルを格納できる動的スキーマを備えた NoSQL データベースです。 ドキュメントのインデックス作成、変換、および結合は、CouchDB の JSON データ交換フォーマットで可能であり、JavaScript を使用してドキュメントのインデックス作成、変換、および結合を行います。 Oracle NoSQL Databaseは、キー値およびJSON表データ・モデルに加えて、キー値およびJSON表データ・モデルをサポートしています。
オンプレミスまたはクラウドで実行するように設計されています。 InfiniteGraph は、モデルベースのグラフ データを含む非常に特殊なグラフ データベースです。 クラウドを利用し、スケーラブルで、プラットフォーム自体を含むあらゆるレベルで高スループット データを処理できます。 クエリ言語は、複雑なグラフと値ベースのクエリを処理するように設計されています。 このソリューションの最も一般的な用途は、医療、電気通信、サイバーセキュリティ、金融、製造、およびネットワークです。
構造化データとは対照的に、スキーマレス ストレージでは、分析のためのより柔軟で機敏なデータ モデルが可能になります。 データを正規化できないため、検索データベースではスキーマ定義の値が低くなります。 ドキュメント ファイルを使用して、データを特定のドキュメントに集約するクエリを生成できます。 Azure Table などのクラウドベースのストレージ プラットフォームを使用して、非リレーショナル構造化データを格納できます。 スキーマレスであるため、アプリケーションの複雑化に合わせてデータを簡単に調整して、アプリケーションのニーズを満たすことができます。 さらに、NoSQL 検索データベースは、半構造化データの分析用に設計されていますが、テーブル ストレージは、半構造化データのデータを分析するためのより柔軟で機敏なアプローチを提供します。
クラスター内のデータを編成する 3 つの方法
Cassandra はデータをノードのクラスター間で複製されるテーブルに編成し、データは簡単に読み取りできるように編成されます。 各Cassandra テーブルは、テーブルで使用できる列とデータ型を定義するスキーマによって区別されます。 通常、テーブルはクラスタに編成され、各インスタンスがテーブル スペース全体のサブセットを管理します。 HBase は物理的な場所ごとにデータを編成し、クラスター内に物理的に配置されたテーブルに格納します。 スキーマは、テーブルに格納できるデータの列と型を、対応する列とデータ型と共に定義します。 HBase インスタンスでは、通常、テーブルはリージョンに編成され、各インスタンスはテーブル スペース全体のサブセットを提供します。 Hypertable クラスターでは、データはテーブルに編成され、クラスターのノードに物理的に格納されます。 通常、テーブルはシャードに配置され、各インスタンスがテーブル スペース全体のサブセットを管理します。