
Einführung in die Hasura GraphQL Engine für dynamische APIs mit PostgreSQL
Veröffentlicht: 2019-11-07Im Allgemeinen wurden REST-APIs in den letzten Jahren als unflexibel kritisiert, während sie mit sich schnell ändernden technischen Anforderungen umgehen. Rückblickend glauben viele, dass GraphQL geschaffen wurde, um diesem Bedarf an zusätzlicher Flexibilität und Effizienz bei der API-Entwicklung gerecht zu werden. Dadurch werden die Mängel von REST-APIs gemildert. Als Ergebnis des Übergangs von Facebook von HTML5-Anwendungen zu robusteren und nativeren Setups hat GraphQL in den letzten fünf Jahren aus gutem Grund an Popularität und Akzeptanz gewonnen. In diesem Blog werden wir uns mit dem GraphQL-Phänomen PostgreSQL befassen und später eine gründliche Einführung in die Hasura GraphQL-Engine geben. In einem Ausschnitt die Hasura GraphQL-Engine-PostgreSQL-Beziehung und das Ökosystem.
GraphQL: Eine Facebook-Rebellion
Während viele glauben, dass GraphQL als Rebellion gegen REST-APIs geschaffen wurde, könnte dies weiter von der Wahrheit entfernt sein. Ironischerweise wurde es geschaffen, um einfach ein internes Bedürfnis bei Facebook zu erfüllen. Ursprünglich vom Facebook-Team entwickelt und Open-Source, wird GraphQL oft mit einer Datenbanktechnologie verwechselt. Trotz des Missverständnisses ist GraphQL im Wesentlichen eine Abfragesprache für APIs und nicht für Datenbanken. Folglich wird die Komplexität beim Erstellen von APIs reduziert, indem alle Anforderungen an einen einzigen Endpunkt abstrahiert werden. Im Gegensatz zu herkömmlichen REST-APIs ist GraphQL deklarativ, was bedeutet, dass alles, was angefordert wird, zurückgegeben wird. Um etwas mehr Kontext zu erhalten, müssen wir jedoch einen Schritt zurücktreten und uns die REST-APIs noch einmal ansehen.
Die REST-Architektur
Typischerweise sind APIs Regeln, Routinen oder Protokolle, die festlegen, wie Softwarekomponenten interagieren sollen. Representational State Transfer (REST) ist im Grunde eine API-Designarchitektur, die normalerweise bei der Implementierung von Webdiensten genutzt wird, wo alles als „Ressource“ betrachtet wird. Leider beschränkte sich die RESTful-Methodik konsequent auf den Umgang mit einzelnen Ressourcen. Wenn also Daten benötigt werden und von zwei oder mehr Ressourcen stammen, z. B. Posts und Benutzern, sind mehrere Roundtrips zum Server erforderlich, um alles Benötigte zu sammeln. Außerdem hatte REST Probleme mit dem „Über“- und „Unter“-Abruf. All dies war nicht ideal, insbesondere mit dem Aufkommen von mehr datengesteuerten Apps, die große Datensätze verarbeiten und verwandte Ressourcen kombinieren. Was die missliche Lage von Facebook erklären könnte.
Daher besteht die Notwendigkeit einer API-Architektur, die einen flexibleren und fortschrittlicheren Ansatz verfolgt.
Die Schaffung einer Alternative
Alternativ betrachtet GraphQL Daten nicht in Form von Ressourcen-URLs, Sekundärschlüsseln oder Tabellen, sondern in Form eines Diagramms von Objekten und Modellen, die NSObjects oder JSON verwenden. Insbesondere benötigt GraphQL keine dedizierten Endpunkte pro Anwendungsfall, da verschiedene Fähigkeiten und Anwendungsfälle in einem einzigen „Graphen“ dargestellt werden können. Mit der GraphQL-Abfragesprache können Sie genau beschreiben, wie die Antwort aussehen soll, sodass keine zusätzlichen Server-Roundtrips erforderlich sind. Als Abfragesprache auf Anwendungsebene wurde sie entwickelt , um eine Zeichenfolge von einem Server/Client zu interpretieren und diese Daten in einem stabilen, verständlichen und vorhersagbaren Format zurückzugeben. Es ist einfach ein Werkzeug, um Daten besser zu konsolidieren.
Einfachheit, Stabilität und Effizienz.
Die Wahrheit ist, dass nicht alle Projekte GraphQL trotz seines gut definierten Schemas benötigen, daher wissen wir mit Sicherheit, dass wir nicht überladen werden. Wenn wir jedoch ein Unternehmensprodukt haben, das auf Daten aus mehreren Quellen angewiesen ist, z. B. MySQL, Postgres und andere APIs, dann ist GraphQL die bessere Option. GraphQL ist stolz auf seine Einfachheit, insbesondere in Bezug auf den Datenabruf, da Daten unter einem gemeinsamen Endpunkt oder Anruf gesammelt werden. Da Clients genau das bekommen, was sie brauchen, reduziert dies im Wesentlichen effektiv die Größe jeder vom Client gestellten Anfrage, was zu Hochleistungsanwendungen führt. Da GraphQL Daten vereinheitlicht, die andernfalls mehrere Endpunkte erfordern würden, vereinfacht es komplexe wiederholte Abrufe und verbessert so die Abfrageeffizienz. Folglich bringt seine Einfachheit im Laufe der Zeit mehr Back-End-Stabilität, Planung, Konstruktion, Ausführung und fortgesetzten Betrieb mit sich.
Vorteile von GraphQL
Kurz gesagt, GraphQL ermöglicht die Extraktion von Daten mit leicht verständlichen Abfragen und ermöglicht die schnelle Entwicklung von leichten und schnellen Anwendungen, da auf die Daten direkter statt über einen Server zugegriffen wird. Darüber hinaus ermöglicht es den Abruf mehrerer Ressourcen mit einer Abfrage ohne Verwendung mehrerer URLs oder Verkettung von Ressourcen, während ein Endpunkt für alle Daten verwendet wird. Denken Sie daran, dass die Daten auf dem Server mit einem diagrammbasierten Schema definiert sind und daher als Paket und nicht durch mehrere Aufrufe geliefert werden. Dies ermöglicht eine operative Steigerung der Aggregation von API-Antworten während der API-Entwicklung.
Dies wiederum entlastet die Front-End-Entwicklungsteams, erleichtert die API-Versionierung, vereinfacht die Wartung und spart Datenübertragungsanforderungen ein. Darüber hinaus ermöglicht es mehr Vorhersagbarkeit beim Empfangen von Daten, unterstützt das deklarative Abrufen von Daten und mindert Über- und Unterabruf. Im Wesentlichen tritt Overfetching auf, wenn ein Client mehr Informationen herunterlädt, als tatsächlich in der App erforderlich sind, während Underfetching impliziert, dass ein bestimmter Endpunkt nicht genügend Informationen bereitgestellt hat, sodass der Client zusätzliche Anforderungen stellen muss, um das abzurufen, was er benötigt.
Technisch gesehen ist GraphQL ein Wrapper, der definiert werden kann, was bedeutet, dass Sie ein REST-System nicht vollständig ersetzen müssen. Im Wesentlichen bedeutet dies, dass GraphQL mit Systemen kompatibel ist, mit denen REST-zentrierte APIs kompatibel sind. Darüber hinaus ermöglicht GraphQL eine nahtlose und unabhängige Entwicklung von Front- und Backend. Denn sobald das Schema gut definiert ist, kennen die Teams, die am Front-End und am Back-End arbeiten, die endgültige Struktur der Daten. All diese Vorteile werden von vielen Full-Stack-Ingenieuren als vorteilhaft angesehen. Schließlich hat GraphQL eine erstaunliche Fähigkeit zur gründlichen Selbstbeobachtung und Selbstdokumentation.

GraphQL-Anwendungsfälle in der API-Entwicklung
GraphQL gilt als äußerst leistungsfähig und wird von Full-Stack-Entwicklern verwendet, die eine stabile Lesbarkeit mit hoher Geschwindigkeit und Indizierung suchen. Insbesondere ist GraphQL bei der API-Entwicklung nützlich, die einen hohen Datendurchsatz erfordert. Tatsächlich minimiert es die Datenmenge, die für die Übertragung über ein Netzwerk erforderlich ist. Dies ist sehr vorteilhaft für mobile Benutzer, Geräte mit geringer Leistung und schlampige Netzwerke. Dies ist einer der ursprünglichen Gründe, warum Facebook GraphQL entwickelt hat. Entgegen der landläufigen Meinung ist GraphQL nicht nur in riesigen, komplexen Datenbanken anwendbar, es kann auch relativ einfache Datenbanken mit größerer Effizienz erstellen.
Darüber hinaus kann es auf einer Vielzahl einzigartiger Front-End-Frameworks und -Plattformen angewendet werden, wodurch eine heterogene Landschaft bereitgestellt wird, die mit einer API verwaltet wird, um allen Benutzeranforderungen gerecht zu werden. Darüber hinaus erleichtert es die schnelle Feature-Entwicklung, da es die Feature-Geschwindigkeit für Full-Stack-Entwicklerteams dramatisch erhöht. Dies wird erreicht, indem die erforderliche Kommunikation zwischen den Teams reduziert wird, während neue Funktionen entwickelt werden, da Front-End-Entwickler API-Anfragen stellen können, um beispielsweise neue Funktionen einzuführen oder vorhandene zu ändern, ohne auf die Lieferung durch Back-End-Entwickler warten zu müssen. Diese kurze GraphQL-Zusammenfassung sollte vorerst ausreichen, da wir mit unserer Einführung in die Hasura GraphQL-Engine beginnen. Lassen Sie uns jedoch PostgreSQL berühren, um etwas mehr Kontext zu erhalten.
Was ist PostgreSQL?
Als kostenloses, von der Community betriebenes Verwaltungssystem für relationale Datenbanken gehört PostgreSQL keinem einzelnen Unternehmen. Postgres gilt als das leistungsstärkste, intern konsistente verfügbare RDBMS, wurde in C geschrieben und unterstützt eine Reihe von Programmiersprachen wie C/C++, JavaScript, Java, Python, R, Go, Lisp, .Net usw. Von den meisten zunehmend bevorzugt Full-Stack-Entwickler ist PostgreSQL funktionsreicher als seine Schwester MySQL und gewinnt aufgrund seiner Funktionen, Skalierbarkeit und Leistung an Popularität. PostgreSQL ist beliebt in Projekten, bei denen sich die Anforderungen um komplexe Verfahren, komplizierte Designs, maßgeschneiderte Integration und Datenintegrität drehen.
Vorteile von Postgres für Full-Stack-Entwickler
Im Allgemeinen geben Funktionen wie Volltextsuche, JSON-Spalten und logische Replikation Postgres gegenüber MySQL die Oberhand. Dies ist optimal für die Leistungsanforderungen typischer kommerzieller Datenbanken und ermöglicht gleichzeitig die Konsolidierung mehrerer Datenbanksysteme zu einem für weniger Aufwand und Kosten. Darüber hinaus machen es seine neueren Features für Key-Value-Storage (JSON / JSONB-Spaltentypen) zu einer geeigneten Alternative zu NoSQL-Datenbanken. Darüber hinaus unterstützt es Clustering oder eine Master-Slave-Architektur, wodurch es sich gut für Cloud-ähnliche Umgebungen eignet. Darüber hinaus ermöglicht die beliebte Foreign-Data-Wrapper-Erweiterung bei Bedarf die Abfrage externer Quellen direkt aus PostgreSQL heraus. Insbesondere eignet es sich am besten für Systeme, die die Ausführung komplexer Abfragen, Data Warehousing und dynamische Datenanalyse erfordern.
Tatsächlich unterstützt PostgreSQL bestimmte Funktionen besser als MySQL. Überprüfen Sie beispielsweise Einschränkungen, reichhaltige Datentypen (z. B. Arrays, Karten, JSON), umfassendere Geodatenunterstützung (PostGIS) und umfassendere Volltextunterstützung. Darüber hinaus unterstützt es die nicht blockierende Indexerstellung, Teilindizes, allgemeine Tabellenausdrücke und dynamischere Analysefunktionen. Ungeachtet dessen bietet PostgreSQL native SLL-Unterstützung für Verbindungen zur Verschlüsselung der Client/Server-Kommunikation sowie eine integrierte Erweiterung namens SE-PostgreSQL, die zusätzliche Zugriffskontrollen basierend auf der SELinux-Richtlinie bereitstellt.
Mit vielen reichhaltigen Funktionen für Produkte der Enterprise-Klasse eignet sich PostgreSQL für große Systeme, in denen Daten eine Authentifizierung erfordern und Lese-/Schreibgeschwindigkeiten für den Projekterfolg entscheidend sind. Darüber hinaus unterstützt es auch mehrere Leistungsverbesserer, die normalerweise in proprietären Lösungen verfügbar sind. Dazu gehören: Parallelität ohne Lesesperren, SQL-Server und Unterstützung für Geodaten, um nur einige zu nennen.

Ein weiterer Hauptvorteil der Postgres-Architektur ist ihre einzigartige Erweiterbarkeit. Benutzer können Funktionen wie Datentypen, Indexzugriffsmethoden, Serverprogrammiersprachen, Foreign Data Wrapper (FDW) und ladbare Erweiterungen hinzufügen, ohne den Code des Kernsystems zu ändern. Er nutzt eine moderne Multi-Core-Prozessorarchitektur und ermöglicht so, dass seine Leistung mit zunehmender Anzahl von Kernen nahezu linear wächst. Dies ist wichtig. Im Allgemeinen geben Funktionen wie Volltextsuche, JSON-Spalten und logische Replikation Postgres gegenüber MySQL die Oberhand. Dies ist optimal für die Leistungsanforderungen typischer kommerzieller Datenbanken und ermöglicht gleichzeitig die Konsolidierung mehrerer Datenbanksysteme zu einem für weniger Aufwand und Kosten. Darüber hinaus machen es seine neueren Features für Key-Value-Storage (JSON / JSONB-Spaltentypen) zu einer geeigneten Alternative zu NoSQL-Datenbanken. Darüber hinaus unterstützt es Clustering oder eine Master-Slave-Architektur, wodurch es sich gut für Cloud-ähnliche Umgebungen eignet. Darüber hinaus ermöglicht die beliebte Foreign-Data-Wrapper-Erweiterung bei Bedarf die Abfrage externer Quellen direkt aus PostgreSQL heraus. Insbesondere eignet es sich am besten für Systeme, die die Ausführung komplexer Abfragen, Data Warehousing und dynamische Datenanalyse erfordern.

Nachteile von PostgreSQL
Wenn Sie ANSI-SQL-Standards bevorzugen, sollten Sie im Allgemeinen PostgreSQL in Betracht ziehen. Wenn Sie jedoch ODBC-Standards bevorzugen, entscheiden Sie sich für MySQL. Leider ist Postgres in Live-Produktionsumgebungen, die „always up“ sind, gelegentlich leistungsschwach. Ein weiterer Nachteil von Postgres ist die Tatsache, dass die Replikation auf der Ebene der Speicher-Engine implementiert wird. Das macht sie teurer als die Replikation von MySQL, die ausgereifter ist und auf der „Abfrage-Engine-Ebene“ implementiert wird.
Einführung in die Hasura GraphQL-Engine
Da wir die GraphQL-API-Entwicklung und PostgreSQL kurz behandelt haben, sollten wir genug Kontext für eine Einführung in die Hasura GraphQL-Engine haben. Im Grunde ist Hasura einfach eine GraphQL-Engine für das PostgreSQL-RDBMS, die eine vereinfachte Möglichkeit zum Bootstrapping und Verwalten der GraphQL-API-Entwicklung bietet. Rückblickend ist Hasura derzeit die einzige leicht verfügbare Lösung, die GraphQL-as-a-Service sofort zu bestehenden PostgreSQL-basierten Anwendungen hinzufügt. Im Wesentlichen wird die zeitaufwändige Aufgabe des Schreibens von Backend-Code, der GraphQL verarbeitet, umgangen.
Hasura vereinfacht
Nehmen wir uns eine Minute Zeit, um Hasura weiter zu vereinfachen. Grundsätzlich sind APIs Schnittstellen, die es Ihnen ermöglichen, Informationen anzufordern (eine Abfrage) und somit durch Senden von JSON- oder XML-Daten zu antworten. Diese Datenbank wird normalerweise von einem Server gehostet und abgerufen. Hier kommt Hasura ins Spiel, um die Dinge zu vereinfachen. Im Nachhinein ist die Hasura GraphQL-Engine ein Server, der Ihre GraphQL-Abfragen über eine Postgres-Datenbank verarbeitet. Dies reduziert effektiv die Zeit, die Ihre App benötigt, um produktionsbereit zu sein, und ermöglicht es Ihnen, Tabellen Ihrer Datenbank mit nur wenigen Klicks zu erstellen, anzuzeigen und zu ändern. Folglich können Full-Stack-Entwickler innerhalb kürzerer Zeit skalierbare GraphQL-Anwendungen auf PostgreSQL erstellen. Dies erspart Entwicklern wochenlanges Programmieren im Voraus und kann verhindern, dass problematische Datenlecks in die Produktion gelangen.
Welches Problem löst Hasura in der API-Entwicklung?
Im Allgemeinen vereinfacht Hasura das API-Lebenszyklusmanagement während des groß angelegten Produktionseinsatzes, insbesondere für komplexe APIs. Vor allem zieht die GraphQL-Engine Full-Stack-Entwickler an, die mit Unternehmens-API-Entwicklungsprojekten unter Verwendung vorhandener PostgreSQL-Datenbanken im Rückstand sind. Da GraphQL blitzschnelle API-Entwicklungszyklen ermöglicht, bietet Hasura idealerweise eine vereinfachte Möglichkeit für Unternehmen, schrittweise auf GraphQL umzusteigen, ohne bestehende Anwendungen, Datenbanken oder Benutzer zu beeinträchtigen. Neben ihrem geringen Gewicht und ihrer hohen Leistung verfügt die Engine über eine Admin-Benutzeroberfläche, mit der Sie Ihre GraphQL-APIs erkunden und Ihr Datenbankschema und Ihre Daten visuell verwalten können.
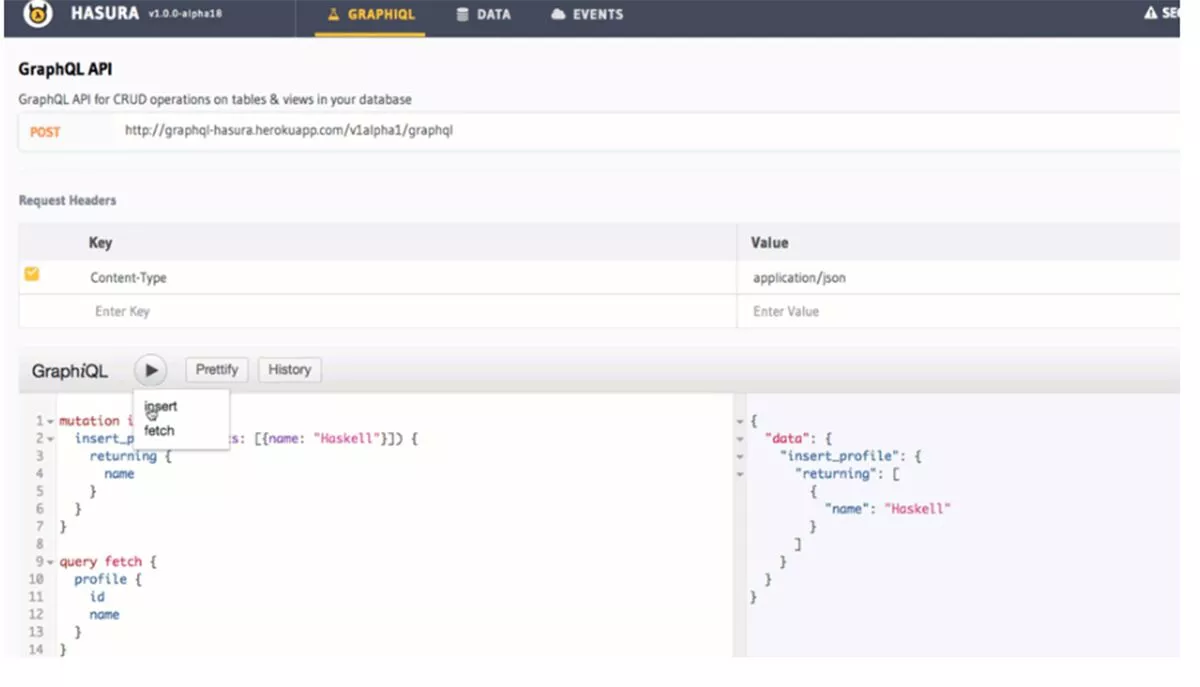
Vorteile von Hasura
Erstens verfügt Hasura über ein solides, stabiles Modell zur Verwaltung von Datenbankänderungen oder „Migrationen“. Dies ist vorteilhaft, da die Datenbankschemaverwaltung oft schwierig ist. Zum Beispiel Aufgaben wie; Verfolgen von Änderungen im Laufe der Zeit und Zuordnen von Schemaänderungen zu API-Verbesserungen (Schemaverwaltung). Darüber hinaus können sich Routineaufgaben wie das Verwalten von Skripts, die eine neue Datenbank bereitstellen oder Änderungen rückgängig machen können, als mühsam erweisen und schwer zu diagnostizierende Fehler oder einen Ausfall verursachen. Positiv anzumerken ist, dass Hasura-Datenbankmigrationskomponenten reines SQL sind und daher außerhalb des Hasura-Toolsets portierbar sind. Alles in allem hat Hasura großartige Schemaverwaltungsfunktionen und Sie müssen keinen Code schreiben, um Web-Socket-Verbindungen zu handhaben.
Zweitens macht es die Hasura GraphQL-Engine einfach, erforderliche Daten mit einer einzigen Abfrage abzurufen. Dies geschieht, indem Sie Ansichten als Beziehungen zu Tabellen oder anderen Ansichten hinzufügen können. Darüber hinaus ermöglicht es das Schreiben von benutzerdefinierten Resolvern mit Schema-Stitching und die Integration von serverlosen Funktionen oder Microservice-APIs, die bei Datenbankereignissen ausgelöst werden. Dies kann sich als nützlich erweisen und erleichtert das Erstellen von 3-Faktor-Apps. Tatsächlich ist Hasura ein extrem leichter Motor. Im Nachhinein verbraucht es nur bis zu 50 MB RAM, selbst wenn mehr als 1000 Anfragen/pro Sekunde verarbeitet werden. Ein brillanter Return on Investment!
Insbesondere erleichtert Hasura die feinkörnige Autorisierung und Authentifizierung auf API-Datenebene weiter. Es ermöglicht die Verbindung zu einem bevorzugten Authentifizierungsanbieter entweder über Webhook, JWT, Auth0 oder benutzerdefinierte Implementierungen. Und damit die Spezifikation von Rollen für Benutzer, die definieren, wer auf verschiedene Daten zugreifen kann, z. B. Administrator, anonyme Benutzer usw. Im Allgemeinen basiert sein granulares Zugriffskontrollsystem auf der Datenbanktabellenstruktur ähnlich dem GraphQL-Schema. Darüber hinaus werden benutzerdefinierte Berechtigungsregeln streng auf der Grundlage von Datenbankvorgängen und -werten definiert.
Schließlich unterstützt Hasura auf brillante Weise effizientes Paging mit einem einfachen SQL-ähnlichen Offset/Limit-Modell. Beispielsweise verwendet es das Zugriffssteuerungsmodell, um die Anzahl der Zeilen einzuschränken, die für eine bestimmte Abfrage zurückgegeben werden. Sein Modell ermöglicht die Anpassung der Grenzwerte nach Rolle. Beispielsweise sind Benutzer, die eine viel höhere Anforderungsrate auferlegen, auf kleinere Zeilenlimits beschränkt. Dadurch wird eine Belastung der Datenbank und der GraphQL-Engine vermieden. Darüber hinaus beschränkt Hasura Sie nicht nur auf GraphQL. Sie können weiterhin REST- oder andere Nicht-GraphQL-Mikrodienste für die von Hasura verwalteten Postgres-Tabellen ausführen. Dies ist mit Hasuras automatischem Schema-Stitching möglich. Dies ermöglicht die Zusammenführung eines Nicht-Hasura-GraphQL-Dienstes und Back-Ends für ein einziges einheitliches Schema, das neue, von Hasura verwaltete APIs mit Legacy-APIs und -Daten kombiniert.
Hasura-Anwendungsfälle
Die Hasura Engine ist für Hochleistungsumgebungen geeignet und bietet Geschwindigkeit bei gleichzeitiger Automatisierung der GraphQL-Postgres-Implementierung in bestehenden Datenbanken. Folglich bietet dies Unternehmen, die bereits Postgres verwenden, eine weniger stressige und schrittweise Möglichkeit, auf GraphQL umzusteigen, indem sie vorhandene Tabellen zu einem „Diagramm“ verknüpfen. Hasura kümmert sich effizient um das Schema-Stitching, sodass Sie ganz einfach benutzerdefinierte Geschäftslogik anwenden können. Mit Remote-GraphQL-Schemata kann Hasura als Gateway für benutzerdefinierte Geschäftslogik genutzt werden, sodass Sie in Ihrer bevorzugten Sprache auf GraphQL-Server schreiben und die Daten später einem einzelnen Endpunkt zur Verfügung stellen können. Darüber hinaus verfügt Hasura über eine großartige Syntax für Abfragen und Mutationen mit integrierten Live-Abfragen, die in GraphQL als Abonnements bezeichnet werden.
Die wenigen Hasura-Einschränkungen
Leider funktioniert das Zugangskontrollsystemmodell von Hasura nicht für jede Anwendung vollständig. Beispielsweise wird die Autorisierung des API-Zugriffs auf der Ebene einzelner Eingabeparameter nicht vollständig unterstützt. Ganz zu schweigen von der Tatsache, dass es in den meisten Fällen auf die Postgres-Datenbank beschränkt ist, die eine Migration erfordert. Obwohl vernachlässigbar, sind die Fehlermeldungen, die die GraphQL-API für fehlerhafte Anfragen zurückgibt, auf Hasura ziemlich unfreundlich. Ansonsten gibt es wenig, was Hasura nicht kann, wie wir in dieser Einführung in die Hasura GraphQL Engine gesehen haben.
Fazit
Zusammenfassend lässt sich sagen, dass GraphQL mit zunehmendem Wachstum die API-Entwicklung in Unternehmen wesentlich vereinfachen wird, um sie im Webmaßstab zu erstellen. Mit der breiten und schnellen Einführung von GraphQL in einer Vielzahl von Branchen hat Hasura das Potenzial, die Erstellung und Verwaltung von APIs mit branchenüblichen Technologien der Wahl, GraphQL und Postgres, weiter zu automatisieren. Hasura vereinfacht die Erstellung von CRUD (Erstellen, Lesen, Aktualisieren und Löschen) GraphQL-Backends. Noch wichtiger ist, dass Hasura bei weitem die beste und einzige Option ist, wenn Sie mit einer GraphQL-zentrierten API und Postgres bei Null anfangen, ohne Backend-Code schreiben zu müssen. Bei Fragen oder Beratungen zu den Möglichkeiten von GraphQL und Hasura für Unternehmen können Sie sich gerne an uns wenden. Das war es für unsere Einführung in die Hasura GraphQL Engine.