
Przechowywanie bazy danych NoSQL dla polubień
Opublikowany: 2022-12-07Jeśli używasz bazy danych NoSQL do przechowywania danych , istnieje kilka różnych sposobów przechowywania polubień. Najpopularniejszym sposobem jest przechowywanie danych w formacie JSON. W ten sposób możesz przechowywać dane w parze klucz-wartość, przy czym kluczem jest identyfikator użytkownika, a wartością liczba polubień. Możesz także przechowywać dane w formacie XML, który jest podobny do JSON, ale używa nieco innej składni.
Czy Nosql może przechowywać dane relacji?
Relacje mogą być przechowywane w bazach danych NoSQL, ale różnią się one od baz danych, które je obsługują. Wielu użytkowników baz danych NoSQL uważa, że modelowanie danych relacji w bazach danych NoSQL jest łatwiejsze niż modelowanie danych w relacyjnych bazach danych, ponieważ powiązanych danych nie trzeba oddzielać od powiązanej tabeli.
Obiektów nie można łączyć ze sobą za pomocą bazy danych zorientowanej na dokumenty (NoSQL). W tym wpisie na blogu wyjaśniono, w jaki sposób można przestać przejmować się obiektami/relacjami w bazie danych, rezygnując z pracy. Realizowany jest proces dodawania obiektów do relacji wywołaniem REST API. W tym przykładzie użyjemy czasownika PUT, aby powiązać klienta z określonym problemem, a także z osobą odpowiedzialną. Relacja jest zawsze reprezentowana w sensowny sposób. Baza danych będzie śledziła wszelkie zmiany dokonane w oryginalnym dokumencie po każdym odwołaniu do obiektu (tj. relacji). Oprócz śledzenia wszystkich relacji, baza danych może nam powiedzieć, gdzie dany dokument jest używany w relacji. Aby śledzić niejawne odniesienia, zapoznaj się z poniższą tabelą i użyj specjalnego zapytania.
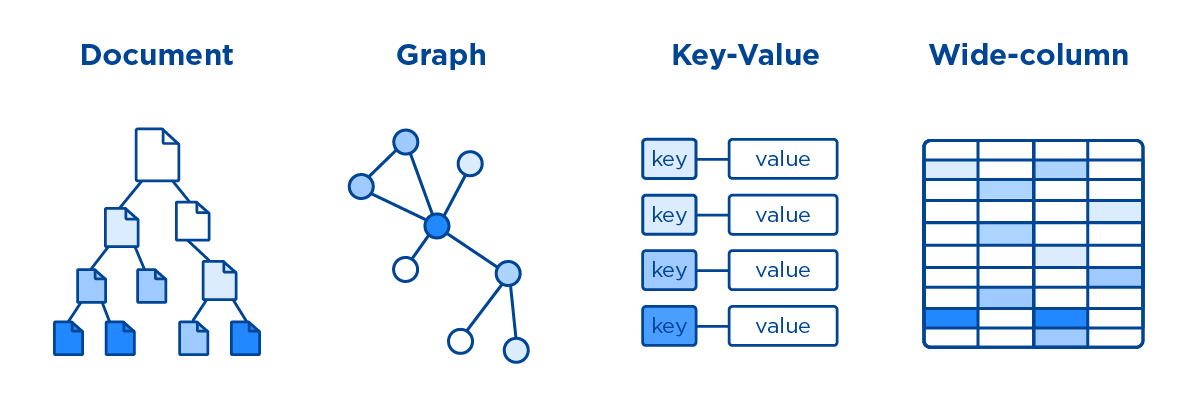
Różne typy baz danych Nosql
Decydując, której bazy danych użyć, bardzo ważne jest zrozumienie danych, które będą przechowywane. Mimo że bazy danych NoSQL przechowują dane w dokumentach, a nie w tabelach relacyjnych , klasyfikuje się je jako modele SQL lub elastyczne modele danych. Bazy danych NoSQL mają możliwość skalowania, dobrej wydajności i stabilności. Korzystając z tych programów, dane można przetwarzać szybko i skutecznie bez konieczności stosowania skomplikowanych systemów zarządzania bazami danych. Chociaż w niektórych przypadkach mogą odnieść sukces, jest mało prawdopodobne, aby całkowicie zastąpiły relacyjne bazy danych. Można ich używać do przechowywania danych, które nie muszą być zorganizowane w formie tabeli.
Co możesz przechowywać w bazie danych Nosql?

Istnieje wiele różnych typów baz danych NoSQL, z których każda jest przeznaczona do przechowywania określonych typów danych. Na przykład magazyny klucz-wartość są przeznaczone do przechowywania danych w prostym formacie klucz-wartość, podczas gdy bazy danych dokumentów są przeznaczone do przechowywania danych w formacie podobnym do JSON.
Bazy danych Document NoSQL przechowują dane w plikach, a nie w wierszach. Dzięki temu są w stanie sprostać wymaganiom nowoczesnego zarządzania danymi biznesowymi na różne sposoby, w tym dzięki elastyczności, skalowalności i reagowaniu na szybko zmieniające się wymagania. Bazy danych dokumentów, magazyny klucz-wartość, bazy danych z szerokimi kolumnami i bazy danych grafów to przykłady baz danych NoSQL. Firmy z listy Global 2000 szybko wdrażają bazy danych NoSQL do obsługi aplikacji o znaczeniu krytycznym. Te pięć trendów powoduje, że większość baz danych boryka się z wyzwaniami technicznymi. Ze względu na ich stały model danych, relacyjne bazy danych są główną przeszkodą w zwinnym rozwoju. Model aplikacji definiuje model danych w NoSQL.
W NoSQL danych nie można modelować po prostu wybierając je z bazy danych. Standard JSON jest najczęściej używanym formatem przechowywania danych w bazie danych zorientowanej na dokumenty. Eliminuje to potrzebę stosowania frameworków ORM, a także konieczność narzutu na tworzenie aplikacji. Do Couchbase Server 4.0 dodano N1QL (wymawiane nikiel), potężny język zapytań, który jest używany do rozszerzenia SQL do formatu JSON. Obsługuje również standardowe instrukcje SELECT / FROM / WHERE, a także agregację (GROUP BY), sortowanie (SORT BY), łączenie (LEFT OUTER / INNER) i inne funkcje. Korzyści z rozproszonych baz danych NoSQL wykraczają daleko poza wydajność; są zbudowane z architekturą skalowalną w poziomie i nie mają pojedynczego punktu awarii. Dostępność aplikacji staje się coraz ważniejsza w dobie zaangażowania klientów online za pośrednictwem aplikacji internetowych i mobilnych.

Bazy danych NoSQL są proste w instalacji, konfiguracji i skalowaniu. Celem urządzeń była pomoc ludziom w organizowaniu ich informacji, w tym pisemnych notatek, dokumentów i przechowywania. Są dostępne do użycia w dowolnej wielkości, niezależnie od tego, czy zarządzasz małym, czy dużym klastrem. Dzięki rozproszonej bazie danych NoSQL do replikacji danych między centrami danych nie jest wymagane żadne oddzielne oprogramowanie. Może również umożliwić natychmiastową awarię za pośrednictwem routerów sprzętowych, eliminując potrzebę czekania przez aplikacje na wykrycie problemu przez bazę danych i przeprowadzenie własnego odzyskiwania. W ciągu najbliższych kilku lat technologia baz danych NoSQL będzie odgrywać coraz większą rolę w rozwoju dzisiejszych aplikacji internetowych, mobilnych i Internetu rzeczy (IoT).
MongoDB, oprócz tego, że jest prosty w użyciu, ma usprawniony interfejs, co czyni go idealnym wyborem dla dynamicznych stron internetowych i aplikacji internetowych. Można go również skalować, aby sprostać potrzebom dużych projektów ze względu na jego skalowalność. Baza danych MongoDB jest warta rozważenia w każdym projekcie, który wymaga rozwiązania NoSQL .
Nosql vs Sql: co jest lepsze pod względem wydajności i łatwości użytkowania?
Bazy danych NoSQL są często szybsze niż bazy danych SQL , ponieważ nie wymagają indeksowania. Ponadto ich wydajność jest lepsza niż w przypadku tradycyjnych centrów danych w przypadku dużych wolumenów. Ponieważ wiele baz danych NoSQL ma być prostych w użyciu, są one popularne wśród programistów.
Czy Nosql jest dobry do analiz?
Bazy danych Nosql są często szybsze i bardziej skalowalne niż tradycyjne relacyjne bazy danych , co czyni je dobrym wyborem dla aplikacji analitycznych, które muszą obsługiwać duże ilości danych. Jednak bazy danych nosql mogą być trudniejsze do przeszukiwania i mogą nie obsługiwać wszystkich funkcji, których potrzebują niektórzy użytkownicy.
Jeśli szukasz rozwiązania BI dla swoich danych Mongo, nasza strona MongoDB Analytics jest dobrym miejscem do rozpoczęcia. W ciągu ostatnich kilku tygodni toczyło się wiele dyskusji na temat tego, czy instancje MongoDB powinny być wykorzystywane do analizy danych. W tym artykule omówimy różnice między opartymi na dokumentach bazami danych NoSQL, takimi jak MongoDB, a tradycyjnymi relacyjnymi bazami danych, takimi jak SQL (znanymi również jako relacyjne bazy danych). Miliony programistów korzysta z MongoDB, jednej z najpopularniejszych baz NoSQL. Niektóre firmy pomagają firmom w skutecznym przenoszeniu ich danych do hurtowni danych. Jeśli chcesz przeprowadzać analizy z danymi MongoDB, możesz użyć wersji relacyjnej zamiast wersji SQL. W ramach tajnego sosu Knowi firma rozwija wirtualizację danych.
Użytkownicy mogą wyszukiwać dane w MongoDB i manipulować nimi bezpośrednio za pośrednictwem naszej usługi, ale zapewniamy do tego interfejs wysokiego poziomu. Oprogramowanie typu „wskaż i kliknij” oraz natywne zapytania MongoDB są dostępne do tworzenia zapytań. Wszystko to odbywa się w czasie rzeczywistym na działającej instancji MongoDB, więc nie ma potrzeby przekształcania danych. Nie ma wątpliwości, że MongoDB jest pierwszą bazą danych i nie będzie ostatnią. Oprócz danych MongoDB, użytkownicy mogą łatwo analizować, analizować dane i wizualizować je w czasie rzeczywistym, korzystając z możliwości analizy danych i wizualizacji danych MongoDB. Istnieje mnóstwo dobrych dostawców rozwiązań, którzy pracują nad najnowocześniejszymi podejściami do skalowania analiz w MongoDB.
Baza danych NoSQL jest lepszym wyborem dla firm, które chcą obsługiwać ogromne ilości zróżnicowanych i nieustrukturyzowanych danych w krótszym czasie, określanym mianem Big Data . Stały model schematu nie może być replikowany w ten sposób, jest bardziej elastyczny w przechowywaniu i przetwarzaniu danych oraz skaluje się w poziomie dzięki wykorzystaniu fragmentacji.