
Por qué Apache HBase es la mejor opción para su próximo proyecto de Big Data
Publicado: 2022-11-16Apache HBase es una base de datos distribuida, no relacional y de código abierto modelada a partir de Bigtable de Google y está escrita en Java. Se desarrolla como parte del proyecto Apache Hadoop de Apache Software Foundation y se ejecuta sobre HDFS (Sistema de archivos distribuido de Hadoop), proporcionando capacidades similares a las de Bigtable para Hadoop. Al igual que Bigtable, HBase está diseñado para manejar grandes cantidades de datos con un alto rendimiento y es adecuado para aplicaciones que requieren un acceso de baja latencia a los datos.
HBase, una base de datos NoSQL, se utiliza para almacenar y recuperar datos con acceso aleatorio. El modelo de datos que contiene es dinámico y flexible, lo que le permite almacenar cualquier tipo de datos sin restricciones. HBase se puede integrar con MapReduce de Apache Hadoop para realizar operaciones masivas (por ejemplo, indexación, análisis, etc.). HBase es una base de datos dispersa, multidimensional y ordenada basada en mapas con múltiples versiones de un solo registro. Con el soporte integrado de Hadoop MapReduce , puede manejar grandes cantidades de datos a la velocidad del rayo y en paralelo. La arquitectura HBase se compone de cuatro componentes principales: HMaster, HRegion, Hlog y HBase. ZooKeeper es un proyecto de código abierto que brinda varios servicios esenciales, además de brindar varias características esenciales.
ZooKeeper incluye una característica que permite la sincronización distribuida de datos de configuración. Cuando un nodo falla en HBase, zkQuorum genera mensajes de error y comienza a repararlo. El petróleo y el petróleo, el marketing y la publicidad, la banca y el mercado de valores son solo algunos de los dominios en los que se utiliza HBase.
Como sistema de archivos distribuido, el uso de HDFS en HBase tiene algunas ventajas. La base de datos puede almacenar grandes conjuntos de datos, incluso miles de millones de filas, en un corto período de tiempo, lo que le permite brindar un análisis rápido.
Emplea un enfoque no relacional orientado a columnas para la gestión de bases de datos. La información se almacena en columnas individuales y se indexa utilizando una clave de fila única que es única para cada columna. Esta arquitectura proporciona una recuperación rápida y eficiente de filas y columnas individuales, así como un proceso de escaneo eficiente para columnas individuales en una tabla.
Apache Hbase Nombre de la empresa Sitio web Ingresos Facebook www.Facebook.com $ 117 mil millones Hortonworks Inc www.hortonworks.com 75 millones JP Morgan Chase www.JPMorganChase.com 130 mil millones Palo Alto Networks Inc www.palo Alto
En MongoDB, hay varios tipos de proyecciones, filtrado y funciones agregadas para elegir. A diferencia de Hbase, que empareja datos con valores clave, los valores clave se pueden compartir con otras aplicaciones. MongoDB le permite realizar búsquedas de texto proporcionando índices de texto nativos así como replicación de datos HBase .
¿Es Hadoop una base de datos Nosql?

Hadoop es un marco de software de código abierto para almacenar y procesar grandes datos. Utiliza un sistema de archivos distribuido (HDFS) y MapReduce para procesar y analizar datos. Hadoop no es una base de datos relacional tradicional, pero puede usarse para almacenar y procesar datos de manera similar.
En MongoDB, no hay necesidad de documentos porque la base de datos se basa en el modelo de datos de notación de objetos de JavaScript (JSON). Está destinado a ser rápido y simple de usar, así como a tener un índice bien definido y capacidades de búsqueda. Se utiliza un algoritmo de asignación/reducción para procesar conjuntos de datos masivos en Hadoop, un sistema de almacenamiento distribuido. Este producto está diseñado para proporcionar una solución rentable para el análisis y archivo de datos.
¿Hbase usa Sql?
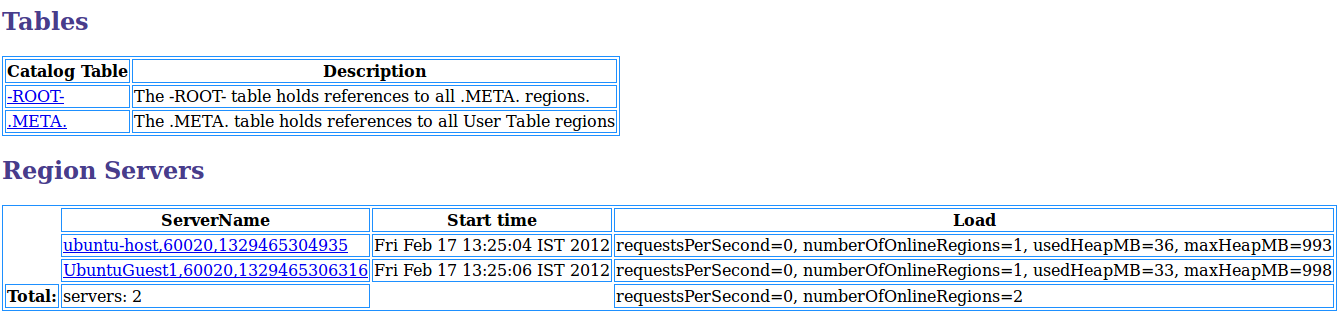
HBase no es una base de datos relacional y no utiliza SQL para consultar datos. HBase utiliza un diseño de almacenamiento de clave/valor que está optimizado para un acceso rápido de lectura/escritura a grandes conjuntos de datos.
Debido a su alta escalabilidad, la compatibilidad con la programación de reducción de mapas de Hadoop y la implementación del conocido documento técnico de Google BigTable, HBase es una excelente opción para el almacenamiento de datos no estructurados. La facilidad de uso de HBase es un gran atractivo para las aplicaciones de almacén que necesitan procesar grandes cantidades de datos rápidamente.
¿Qué es el lenguaje de consulta de Hbase?
El lenguaje de consulta HBase de Jaspersoft, que es un lenguaje declarativo de estilo JSON, le permite especificar qué datos recuperar de HBase. Cuando se utiliza la interfaz del servidor REST de HBase, el conector convierte la consulta en una llamada de API adecuada, que luego se ejecuta en la instancia de HBase .
Los beneficios de usar una tabla Hbase
¿Qué es la familia de columnas? Una familia de columnas puede hacer referencia a una colección de columnas que comparten un nombre y un tipo de datos comunes. Los nombres de los empleados pueden incluir las columnas id, nombre, contratado_en, despedido_en. ¿Cuáles son los beneficios de usar tablas HBase ? Una tabla HBase ofrece las siguientes ventajas: El diseño orientado a columnas de HBase facilita el almacenamiento y el acceso a datos dispersos o no estructurados. Debido a su naturaleza tolerante a fallas, HBase puede resistir la pérdida o corrupción ocasional de datos. Debido a que HBase es tan simple de usar, puede comenzar rápidamente a usar el almacenamiento de big data. Debido a que HBase es escalabilidad, puede agregar más servidores a su clúster para manejar conjuntos de datos más grandes.
¿Para qué no es bueno Hbase?
Las funciones como SQL no se pueden ejecutar utilizando HBase HBase . Debido a que no admite la estructura SQL, no hay optimización de consultas. HBase hace un uso intensivo de la CPU y la memoria, con un gran acceso secuencial de entrada o salida, mientras que los trabajos de Map Reduce suelen estar vinculados a la entrada o la salida con memoria fija y hacen un uso intensivo de la CPU y la memoria.
Hbase: la mejor solución de almacenamiento de datos para operaciones aleatorias de lectura y escritura
Es ideal para aplicaciones que realizan operaciones de lectura y escritura aleatorias, así como para aquellas que utilizan operaciones de lectura y escritura aleatorias. HBase también es una buena opción para aplicaciones que requieren acceso a datos en tiempo real.
¿Hbase es como Cassandra?
A diferencia de Cassandra, que se ejecuta en varios servidores y versiones del mismo archivo, Hbase se ejecuta en un servidor de datos. Como resultado, las lecturas de Hbase son más fáciles de acceder que las lecturas de Cassandra. Los datos de Hbase se almacenan en HDFS, donde tiene filtros de floración y cachés de bloques que le permiten realizar lecturas más rápidas.
Estas bases de datos NoSQL, que pueden manejar grandes conjuntos de datos, fueron creadas por Cassandra y HBase. Comparten muchas características en común, incluidos sus rasgos comunes. A primera vista, ambos son distintos. En este artículo, veremos cómo HBase y Cassandra difieren en términos de los factores involucrados. Cassandra, como HBase, tiene infraestructura Hadoop , pero también tiene diferentes DBMS e infraestructura. Cassandra no requiere ningún poder de cómputo adicional. La indexación a través de filtros de floración es lo que hace HBase.
Con Cassandra, se pueden replicar varias filas desde una sola dirección WAN con particiones aleatorias. Es preferible tener una sola fuente de datos en lugar de múltiples fuentes de datos sobre Cassandra. Además, la instalación de Cassandra Cluster es más sencilla que la de HBase Cluster .
Hbase Vs Cassandra: ¿Cuál es mejor?
Tanto Cassandra como HBase se pueden leer y escribir al mismo tiempo, pero Cassandra es más rápido. Además, Cassandra es más rápida que HBase.
Hbase vs mongodb
No hay un claro ganador al comparar HBase y MongoDB. Ambos sistemas tienen sus propias fortalezas y debilidades. HBase es más adecuado para manejar grandes cantidades de datos, mientras que MongoDB es más flexible y fácil de usar.
Después de 4 años con la base de datos, nos cambiamos a MongoDB y la transición fue perfecta. A pesar de recibir soporte empresarial, tuvimos una experiencia terrible con Couchbase. En la búsqueda de texto completo, con frecuencia se devuelven múltiples tipos de resultados si ejecuta una variedad de consultas. No hay forma de configurar los índices correctamente en Windows. Un servidor de producción puede admitir hasta seis usuarios. Además de manejar el caché en memoria, Couchbase incluye una instancia más pequeña de Memcached. Cada uno de los 5000 documentos ocupa 8 GB de RAM. ¡No hay duda de ello! Había menos de 5000 documentos en una instancia de Couchbase, menos de 20 índices y el consumo de RAM siempre superaba los 8 GB.
La principal distinción entre Amazon DynamoDB y Apache HBase es que Amazon DynamoDB se basa en HDFS, que proporciona búsquedas (y actualizaciones) de registros rápidas para tablas grandes. Un sistema de archivos distribuido, como HDFS, es ideal para almacenar archivos de gran tamaño. HBase, por otro lado, se basa en HDFS y puede realizar búsquedas (y actualizaciones) de registros para tablas grandes con facilidad.
Además, Amazon DynamoDB es una clave/valor y un almacén de documentos, a diferencia de Apache HBase, que es una clave/valor y un almacén de documentos. Para una comparación más completa de Amazon DynamoDB y Apache HBase como almacenes de datos NoSQL, considere el modelo de datos clave/valor para Amazon DynamoDB.

Hbase Vs Mongodb: ¿Cuál es la mejor base de datos?
Con HBase, es fácil almacenar y consultar grandes cantidades de datos. Este sistema basado en la nube es adaptable, duradero y tiene una serie de características únicas que lo convierten en una opción ideal para una amplia gama de empresas. MongoDB es una excelente base de datos NoSQL para aplicaciones que hacen un uso intensivo de la memoria, pero Hadoop proporciona una mejor gestión del espacio.
Hbase Vs Cassandra
La plataforma Hbase se usa para el almacenamiento de datos en grandes bases de datos, mientras que la plataforma Cassandra se puede usar para la ingesta y el almacenamiento de datos de grandes cantidades. En tiempo real, lo mejor es utilizar Cassandra para el procesamiento de transacciones y datos interactivos.
(Almacenamiento) Cassandra vs Hbase: ¿cuál es la diferencia? Apache Cassandra se considera una clase de sistema NoSQL porque está diseñado para crear los repositorios de matrices de datos más estables y escalables. Los usuarios de Cassandra pudieron contribuir a la comunidad utilizando su componente de código abierto, lo que les permitió discutir todos los problemas y consultas. El sistema de administración de bases de datos de Cassandra es extremadamente eficiente. Los desarrolladores podrán aprovechar las capacidades de varias máquinas multinúcleo. La columna de Cassandra contiene el peso de la preferencia del usuario en filas. La infraestructura de Hadoop, que incluye Zookeeper, Hbase master, nodos de datos y nodos de nombres, se utiliza para ejecutar Hbase.
Cassandra emplea un lenguaje de consulta específico y CQL modelado a partir de SQL. El protocolo Zookeeper se utiliza para recopilar datos por parte de otros nodos. Cassandra, por otro lado, se adapta mejor a la ingesta y el almacenamiento de datos a gran escala que Hbase, que se utiliza para almacenar información pequeña en bases de datos grandes.
Por qué Cassandra es la mejor solución Nosql para Netflix
En el mundo de Cassandra y HBase, son muy diferentes. La arquitectura de HBase está diseñada para admitir solo la administración de datos, mientras que la arquitectura de Cassandra está diseñada para admitir el almacenamiento y la administración de datos sin depender de ningún otro sistema.
HBase es utilizado actualmente por varias organizaciones y es utilizado internamente por todas. Cuando necesitamos una tienda NoSQL, puede resolver una amplia gama de problemas y proporcionar una variedad de soluciones únicas. Las soluciones de almacenamiento NoSQL de HBase son las mejores del mercado.
Cassandra, además de ser un componente de infraestructura para el servicio de streaming distribuido globalmente de Netflix, también está disponible en Amazon Web Services.
Base de Apache
HBase es una tienda de código abierto, distribuida y orientada a columnas que sigue el modelo de Bigtable de Google. Así como Bigtable aprovecha el almacenamiento de datos distribuido proporcionado por Google File System, HBase proporciona capacidades similares a las de Bigtable además de Hadoop y HDFS. Las características de HBase incluyen escalabilidad lineal y modular, lecturas y escrituras de baja latencia consistentes y fragmentación automática y configurable de tablas.
Hadoop almacena y procesa cantidades masivas de datos utilizando el sistema de archivos distribuido y MapReduce. HBase, que es una base de datos distribuida orientada a columnas, está construida sobre Hadoop. El proyecto es de código abierto y escalable horizontalmente. La gran tabla de Google, que es similar a la de Google, permite el acceso aleatorio a datos estructurados. HBase, por otro lado, se encuentra en la parte superior del sistema de archivos Hadoop y proporciona acceso de lectura y escritura al sistema de archivos. El sistema de archivos HDFS se puede utilizar para almacenar datos, ya sea directamente o a través de HBase. HBase, una base de datos orientada a columnas, está estructurada de tal manera que se ordenan las filas. Una tabla puede tener más de una familia de columnas y cada familia de columnas puede tener más de una columna.
Hadoop vs. Hbase
Hadoop maneja conjuntos de datos grandes y dispersos de manera más eficiente. Cuando los datos se manejan en tiempo real, las capacidades de manejo de HBase son superiores a las de otras plataformas.
Hbase contra colmena
Hive y HBase son dos tecnologías diferentes que funcionan en Hadoop, Hive es un motor similar a SQL que ejecuta trabajos de MapReduce y HBase es una base de datos de clave/valor NoSQL. Hive es un motor de consulta sólido que le permite consultar en tiempo real, mientras que HBase es un motor de consulta sólido que le permite consultar en tiempo real.
Apache Hadoop y Apache HBase son dos tecnologías de Big Data distintas que pueden servir para varios propósitos, en casi todos los casos. Todas las tecnologías, a los ojos de los sistemas de big data, deben combinarse entre sí. ¿Cuáles son las diferencias entre Hive y HBase? Apache Hadoop MapReduce y HBase se pueden combinar para crear una base de datos NoSQL. Una de las mayores lagunas en HBase es la falta de servicios, lo que permite la posibilidad de acceso aleatorio. También se sabe que se escala horizontalmente utilizando servidores de región listos para usar, para ser altamente disponible, consistente y solo en el extremo inferior del espectro de base de datos No SQL de latencia. Hadoop se usa de dos maneras distintas: Hive y HBase. Hive es un motor similar a SQL que ejecuta trabajos de MapReduce, mientras que HBase es una base de datos NoSQL con claves y valores. En lugar de tener un competidor, estas dos tecnologías deberían colaborar.
¿Hive o Hbase para su próximo proyecto de datos?
Hive existe desde hace mucho tiempo. El uso de HBase tiene algunas ventajas sobre otros almacenes de datos en el mercado, pero aún está en pañales. Hive es una opción popular para implementaciones de almacenamiento de datos entre muchas organizaciones. Es una excelente opción para situaciones en las que no necesita las funciones completas de una base de datos NoSQL pero aún necesita una tienda NoSQL. Las soluciones de almacenamiento NoSQL de HBase son las mejores del mercado.
Casandra Nosql
Cassandra es una poderosa base de datos NoSQL que es perfecta para aplicaciones que requieren alta disponibilidad y escalabilidad horizontal. Cassandra es fácil de usar y proporciona un sólido conjunto de características que lo convierten en una opción ideal para una amplia variedad de aplicaciones.
Apache Cassandra es un proyecto de la comunidad Apache ampliamente disponible que está disponible gratuitamente. Apache Cassandra permite el almacenamiento y la gestión de datos estructurados y no estructurados de alta velocidad en varios servidores básicos. Cassandra, que funciona en conjunto con Google Bigtable y Amazon Dynamo, permite a los usuarios administrar bases de datos desde cualquier ubicación. Ofrece un alto nivel de disponibilidad y carece de problemas importantes. Cassandra ha sido implementada por algunas de las empresas de TI más grandes. Todos los días, Instagram sube aproximadamente 80 millones de fotos a la base de datos de Cassandra. Está compuesto por Apache Cassandra y MongoDB. Un clúster Cassandra de varios nodos es una forma muy sencilla de escalar fácilmente Cassandra para satisfacer un aumento repentino de la demanda.
¿Es Cassandra Is Nosql?
Se puede distribuir una base de datos NoSQL como Cassandra. Las bases de datos NoSQL son livianas, de código abierto, no relacionales y distribuidas equitativamente en su diseño. Se distinguen por su capacidad para escalar horizontalmente, así como por su capacidad para definir esquemas de manera flexible.
MongoDB Nosql
Los modelos de documentos en MongoDB no son relacionales, lo que los convierte en una base de datos. Se distingue de las bases de datos relacionales tradicionales como Oracle, MySQL y Microsoft SQL Server por ser una base de datos denominada NoSQL (NoSQL = Not-only-SQL).
MongoDB es una de las bases de datos NoSQL más utilizadas y puede almacenar datos en formato JSON. El rendimiento, la escalabilidad y la disponibilidad de MongoDB son similares a los de otros lenguajes analíticos/de secuencias de comandos de bases de datos como SQL, Oracle y Oracle. El propósito de este capítulo es explicar los conceptos y tipos fundamentales de NoSQL.
¿Qué tipo de Nosql es Mongodb?
Una base de datos de documentos se compone de múltiples claves que están unidas entre sí por una estructura de datos compleja. Un documento puede anidarse y contener una variedad de pares clave-valor, pares clave-matriz, etc. MongoDB, como base de datos de documentos, es muy similar a Google Docs.
¿Es Mongodb el mejor Nosql?
La tercera mejor base de datos NoSQL es MongoDB, que está diseñada para servir como una base de datos de documentos de propósito general. Debido a que está orientado a documentos, puede organizar toda su información en una sola ubicación, lo que facilita el acceso a toda ella en un solo tema.
¿Qué base de datos es mejor para usted?
Al final, no hay un ganador claro entre las dos bases de datos, cada una de las cuales tiene fortalezas y debilidades. La base de datos debe adaptarse para satisfacer sus necesidades y preferencias específicas.
¿Cómo funciona Mongodb Nosql?
MongoDB es una base de datos NoSQL que está disponible de forma gratuita. Como base de datos no relacional, puede manejar datos estructurados, semiestructurados y no estructurados, y puede manejar cualquier formato de archivo. Se utiliza un modelo de datos orientado a documentos y un lenguaje de consulta no estructurado. MongoDB, que es extremadamente flexible, puede almacenar y combinar múltiples tipos de datos.
Mongodb: la opción preferida para empresas grandes y pequeñas
MongoDB es una excelente opción para aplicaciones de misión crítica porque puede escalar y tiene un rendimiento excelente. Como resultado, Netflix, Uber y Airbnb se encuentran entre las empresas que lo utilizan para potenciar sus aplicaciones más grandes y exigentes durante años.
La plataforma MongoDB hace que sea fácil de usar para nuevas empresas y pequeñas empresas. Además, es muy adecuado para el almacenamiento en la nube, lo que permite a las empresas escalar hacia arriba o hacia abajo según sea necesario.