
هل سبارك لـ Nosql
نشرت: 2023-02-05Spark هي أداة قوية للعمل مع البيانات ، وخاصة مجموعات البيانات الكبيرة. تم تصميمه ليكون سريعًا وفعالًا ، وهو يدعم مجموعة متنوعة من تنسيقات البيانات ، بما في ذلك قواعد بيانات NoSQL . أصبحت قواعد بيانات NoSQL شائعة بشكل متزايد ، لأنها مناسبة تمامًا للتعامل مع كميات كبيرة من البيانات. يمكن أن يساعدك Spark في الاستعلام عن بيانات NoSQL ومعالجتها بكفاءة.
للعمل بفعالية ، من الضروري إدارة قواعد بيانات التطبيق الخاص بك باستخدام Apache Spark و NoSQL ( Apache Cassandra و MongoDB). الهدف من هذه المدونة هو تقديم نصائح لتطوير تطبيقات Apache Spark باستخدام خلفيات NoSQL. إنها مدينة ملاهي ، و TCP / IP sPark بها جولات في كل من CassandraLand و MongoLand. عندما حاولنا الاستعلام عن بيانات DOE ، بدأ تطبيق Spark الخاص بنا في فصل نفسه عن محوره. الدرس المستفاد هنا هو أنه عندما تستفسر عن Cassandra ، فإن تسلسل المفاتيح مهم. تقدم CassandraLand أيضًا السفينة الدوارة Partitioner ، والتي تعد واحدة من أشهر مناطق الجذب فيها. بينما يستمتع العملاء بركوب الأفعوانية ، يمكن لمشغلي الركوب تتبع من ركبها كل يوم من خلال الاحتفاظ بمعلوماتهم.
في الدرس الأول ، سننتقل إلى إدارة اتصالات MongoDB. عندما تحتاج إلى تحديث معلومات حول متنزه ، مثل حالة العضوية الجديدة في المتنزه التابع لوزارة الطاقة ، يمكنك استخدام فهارس المونجو . يجب استخدام MongoDB و Spark لضمان إدارة اتصالك بشكل صحيح ، وكذلك الفهارس في حالات محددة.
يعد Apache Spark نظام معالجة موزعًا شائعًا مفتوح المصدر ومصمم للاستخدام في أحمال عمل البيانات الكبيرة. تتيح هذه الميزة ، بالإضافة إلى التخزين المؤقت في الذاكرة وتنفيذ الاستعلام المحسن ، استعلامات تحليلية سريعة مقابل كميات كبيرة من البيانات.
باستخدام نفس الرمز تقريبًا ، يكون أكثر كفاءة وتنوعًا ، مما يسمح له بمعالجة البيانات المجمعة والوقت الفعلي في نفس الوقت. نتيجة لذلك ، أصبحت أدوات البيانات الضخمة القديمة قديمة بشكل متزايد بسبب افتقارها إلى هذه الوظيفة.
ما هو نوع قاعدة البيانات شرارة؟
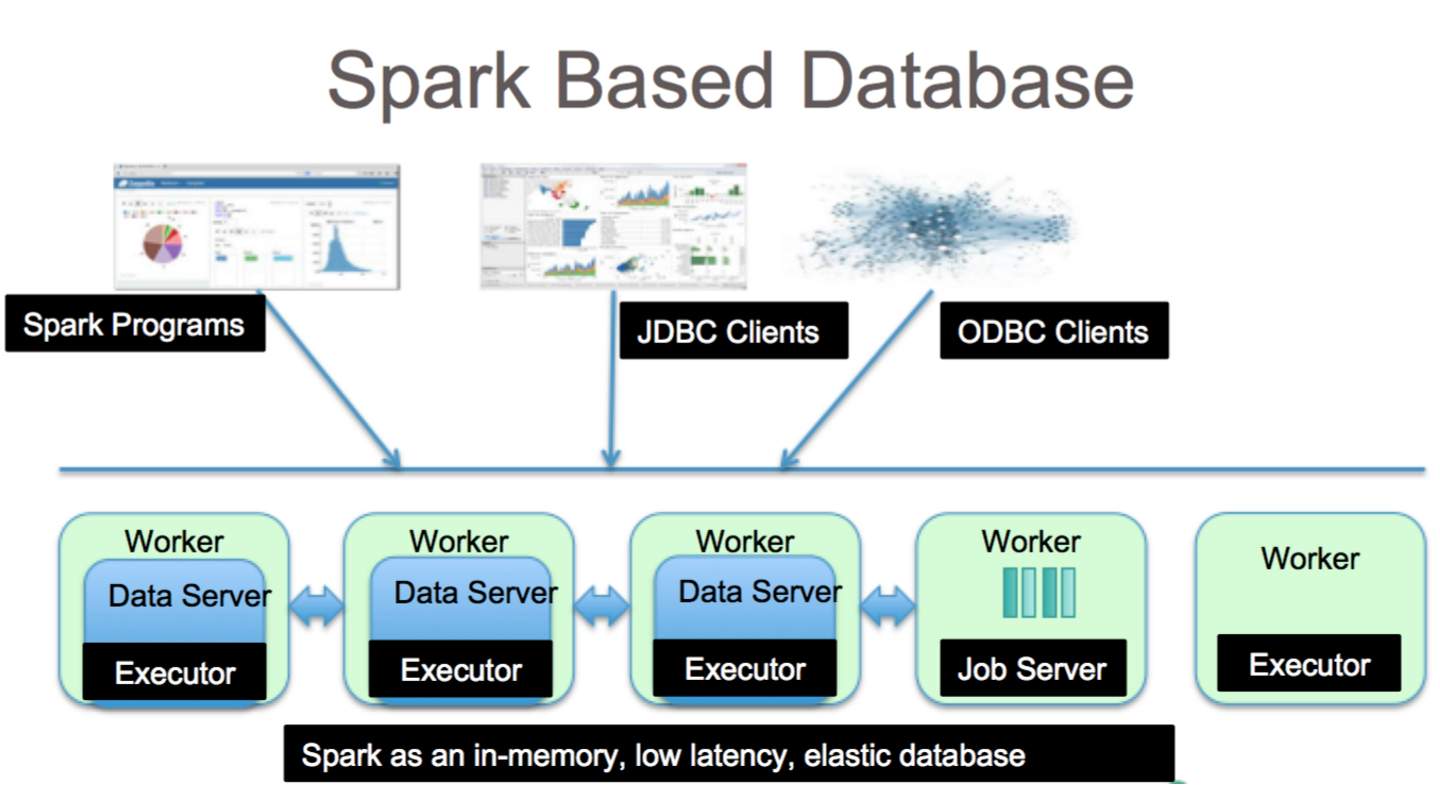
Apache Spark هو إطار عمل لمعالجة البيانات يمكنه التعامل مع البيانات من مجموعة متنوعة من مستودعات البيانات ، بما في ذلك (HDFS) وقواعد بيانات NoSQL وقواعد البيانات العلائقية.
على الرغم من وجود العديد من دورات الضجيج لقواعد البيانات العلائقية ، إلا أنها ستستمر في الانتشار بغض النظر عن أحدث التطورات وصعود قواعد بيانات NoSQL. بمرور الوقت ، أصبح من الصعب بشكل متزايد تخزين البيانات في قواعد البيانات العلائقية. في هذه المقالة ، سنلقي نظرة على بعض التطورات المهمة في الاستفادة من قوة قاعدة البيانات العلائقية على نطاق عالمي. عندما تم إصداره لأول مرة ، كانت الواجهة بين Spark و Big Data Analysis في حدها الأدنى. كتب العديد من الأشخاص الكثير من التعليمات البرمجية لتشغيل هذا البرنامج ، والذي كان قويًا ولكنه بطيء نسبيًا. سيتمكن المستخدمون من دمج هذين النموذجين في قاعدة بيانات Spark SQL بسهولة. كما أنه يقبل مجموعة كبيرة من تنسيقات البيانات من مجموعة متنوعة من المصادر.
يعد مشروع Apache Spark مفتوح المصدر هو الأكثر نشاطًا ، حيث يساهم فيه المئات من المساهمين. بصرف النظر عن كونه مشروعًا مجانيًا مفتوح المصدر ، بدأت Spark SQL تكتسب شعبية في الصناعات السائدة. بالإضافة إلى Spark SQL ، يستخدم ما يقرب من ثلثي عملاء Databricks Cloud (الخدمة المستضافة التي تشغل Spark) لغات برمجة أخرى. بعد الانتهاء من دراسة الحالة الأولى ، سنشرح كيفية تطبيق قواعد البيانات على الحالة في دراسة الحالة العملية هذه. إن Spark DataFrame عبارة عن مجموعة من الصفوف (أنواع الصفوف) التي يتم توزيعها بنفس المخطط. يتم تسمية كل عمود في مجموعة البيانات باسم. تسمح API الخاصة بـ DataFrame للمطورين بدمج التعليمات البرمجية الإجرائية والعلائقية.
يمكن لـ Spark أيضًا التعامل مع الوظائف المتقدمة مثل UDFs. يُعد الجدول الموجود في قاعدة البيانات العلائقية مماثلاً لإطار البيانات في قاعدة بيانات إطار البيانات ، ولكن هناك المزيد من التحسينات المضمنة. يمكن التلاعب بها بنفس الطريقة التي يتم بها التلاعب بمجموعات Spark الأصلية الموزعة (RDDs). بشكل عام ، يكون استعلام Spark SQL أسرع من استعلام Shark وهو أكثر قدرة على المنافسة مع Impulsa. في الاستعلام 3 أ ، حيث تؤدي انتقائية الاستعلام إلى أن يكون أحد الجداول صغيرًا جدًا ، يوجد فرق كبير بين إمبالا وإمبالا.

إنها أداة رائعة لتحليل البيانات باستخدام Spark SQL. يمكن الوصول إلى بناء جملة HiveQL و Hive SerDes و HiveDFs عبر بناء جملة HiveQL ، بالإضافة إلى Hive SerDes و HiveDFs. تم بالفعل تنفيذ خلايا النقائل الخلوية و SerDes و UDFs. على الرغم من حقيقة أن Spark هي قاعدة بيانات ، فهي أيضًا قاعدة بيانات NoSQL. نتيجة لذلك ، عند إنشاء جدول مُدار في Spark ، ستتمكن من استخدام مجموعة متنوعة من الأدوات المتوافقة مع SQL لتخزين بياناتك. يمكن استخدام تعبيرات SQL للوصول إلى الجداول في Spark عن طريق الاتصال بـ JDBC عبر موصلات من jdbc.org. نتيجة لذلك ، يمكنك أيضًا استخدام أدوات الجهات الخارجية مثل Tableau و Talend و Power BI. تعد القدرة على استخدام Spark مثالية لتحليل البيانات ، وهي أداة مفيدة لمجموعة واسعة من الصناعات.
Spark Sql: أفضل ما في العالمين
إنه يسد الفجوة بين النموذجين المذكورين سابقًا ، النماذج الإجرائية والعلائقية ، من خلال تضمين مكونين أساسيين. نتيجة لذلك ، يمكنك تشغيل عمليات ارتباطية واسعة النطاق على مصادر البيانات الخارجية والمجموعات الموزعة المضمنة في Spark باستخدام DataFrame API.
ما هو سبارك في قاعدة البيانات؟ إنه إطار عمل مفتوح المصدر يستخدم التعلم الآلي ومعالجة الاستعلامات التفاعلية وأعباء العمل في الوقت الفعلي. هذه الشركة ليس لديها نظام تخزين خاص بها ؛ بدلاً من ذلك ، تستخدم تحليلات على أنظمة تخزين أخرى مثل HDFS و Amazon Redshift و Amazon S3 و Couchbase وغيرها ، بالإضافة إلى أنظمة التخزين الخاصة بها. عندما يتعلق الأمر بمعالجة البيانات المهيكلة ، فإن Spark SQL ليست مجرد قاعدة بيانات ؛ إنها أيضًا وحدة نمطية. الغالبية العظمى منها مكتوبة على DataFrames ، وهي عبارة عن تجريدات البرمجة التي تعمل جنبًا إلى جنب مع استعلامات SQL.
ما هو نوع SQL SQL لـ “sparksql”؟ يدعم Hive SQL بناء جملة HiveQL ، بالإضافة إلى Hive SerDes و UDFs ، مما يسمح لك بالوصول إلى مستودعات Hive التي تم إنشاؤها مسبقًا. استخدام Hive metastores و SerDes و UDFs الموجودة في Spark SQL ليس بالأمر الصعب.
هل يستطيع Mongodb تشغيل Spark؟

الإصدار 10.0 من MongoDB Connector for Apache Spark يتضمن دعم Spark Structured Streaming عبر Spark Data Sources API V2 الجديد بالإضافة إلى تطبيق Spark Data Sources API V2.
موصل MongoDB لـ Spark هو مشروع مفتوح المصدر يسمح لك بكتابة البيانات من MongoDB وقراءتها من MongoDB باستخدام Scala. نظرًا لطرق الأداة المساعدة للموصلات ، تم تبسيط التفاعلات بين Spark و MongoDB ، مما يجعلها مزيجًا قويًا لإنشاء تطبيقات تحليلية متطورة. باستخدام ميزات النسخ المتماثل والتجزئة المضمنة ، يمكن تنفيذ Spark في مجموعة متنوعة من أحمال العمل التي تستخدم قواعد بيانات MongoDB .
Spark: الطريقة السريعة لإنشاء تطبيقات غنية بالبيانات
بمساعدة Spark ، أداة قوية ، يمكنك تطوير المزيد من التطبيقات الوظيفية بسرعة. من خلال دمج MongoDB ، يمكن للمطورين تسريع عملية التطوير من خلال استخدام تقنية قاعدة بيانات واحدة. علاوة على ذلك ، فإن Spark هي سحابية أصلية وتتضمن دعمًا لمخازن بيانات NoSQL ، مما يجعلها مثالية للتطبيقات كثيفة البيانات.