
Pig: uma plataforma de alto nível para Apache Hadoop
Publicados: 2023-02-22Pig é uma plataforma de alto nível para criar programas executados no Apache Hadoop. O termo “Pig” refere-se à camada de infraestrutura da plataforma, que consiste em um compilador e ambiente de execução, além de um conjunto de operadores de alto nível. A camada de infraestrutura do Pig fornece um conjunto de ferramentas para os desenvolvedores criarem, manterem e executarem seus programas Pig. Pig é um projeto de software livre que faz parte do ecossistema Apache Hadoop . O modelo de programação do Pig é baseado no fluxo de dados, o que facilita a escrita de programas que processam grandes quantidades de dados. Os programas Pig são compostos por uma série de operadores que são executados em um grafo acíclico direcionado. O Pig é uma ótima opção para processar grandes quantidades de dados porque é escalável, eficiente e fácil de usar.
Como solução NoSQL, você precisa de formas específicas e predefinidas para analisar e acessar dados. SQL (UNION, INTERSECT, etc.) é uma expressão de consulta comum que não é usada com muita frequência no mundo do big data. Como o Hive é otimizado para processamento em lote e big data, é melhor tocar em cada linha. O Hive gasta muito menos tempo e dinheiro em operações do que o Hadoop, que tem a vantagem da escala. Mesmo pequenas consultas em sistemas de desenvolvimento podem ser ORDENS de magnitude mais lentas do que consultas semelhantes em RDBMS. O Hive não armazena em cache os resultados da consulta. Reenviar uma consulta repetida é uma prática comum no MapReduce.
Existem dois tipos de Hive: 1) Hive não é um banco de dados; em vez disso, é um mecanismo de consulta que oferece suporte a partes SQL específicas para consultar dados b) Hive é um banco de dados com suporte a SQL c) Hive é um banco de dados específico para SQL. Hive é um sistema de data warehouse baseado em SQL para Hadoop que inclui Pig e Python, entre outras coisas; O Hive é usado para armazenar dados do Hadoop .
Porco é um SQL?
Não há resposta certa ou errada para essa pergunta, pois depende da opinião pessoal. Algumas pessoas podem acreditar que pig é um sql, enquanto outras não. Em última análise, cabe ao indivíduo decidir se o porco é ou não um sql.
Hoje, Apache Hive e Pig são dois termos que estão rapidamente se tornando sinônimos de big data. Com essas ferramentas, os desenvolvedores e analistas de dados podem usá-las para reduzir a complexidade do MapReduce, mantendo um alto nível de integridade dos dados. O Hive é uma infraestrutura de data warehouse também conhecida como ferramenta ETL (extração, carregamento e transformação). Apache Hive, Pig e SQL são três ferramentas populares para análise e gerenciamento de dados. Você deve estar ciente de qual plataforma será a melhor para suas necessidades e com que frequência deve usá-la. Vejamos as três maneiras diferentes de usar Hive, Pig e SQL no contexto dessas três tecnologias. O SQL ainda é o rei do poleiro no gerenciamento e análise de big data, apesar do domínio do Apache Hive e do Apache Pig. Como cada um desempenha uma função específica, seus requisitos são adaptados ao negócio. O Apache Pig é baseado em scripts e requer conhecimento especial, enquanto o Apache Hive é a única solução de banco de dados nativa do desenvolvedor.
O porco é um animal versátil com muita flexibilidade. O Pig, por exemplo, pode processar arquivos de log contendo dados JSON ou XML, permitindo que você leia os dados. Também é possível armazenar dados de serviços da web no Pig.
Tipos de dados de mapa, tuplas e tipos de dados bag podem ser usados de forma intercambiável. Eles são capazes de lidar com dados de qualquer fonte.

O Pig é uma ferramenta Etl?
Não há uma resposta definitiva para essa pergunta, pois depende de como você define uma ferramenta ETL. De um modo geral, uma ferramenta ETL é um aplicativo de software que ajuda a extrair dados de uma ou mais fontes, transformá-los em um formato compatível com seu sistema de destino e carregá-los nesse sistema. Algumas pessoas diriam que o pig é uma ferramenta ETL porque pode executar todas essas funções. Outros podem argumentar que o pig não é uma ferramenta ETL porque não foi projetado especificamente para transformação de dados. Por fim, a resposta a essa pergunta depende de sua própria definição de ferramenta ETL.
Como você pode usar o Pig para processamento ETL?
Um aplicativo Pig pode ser descrito como um modelo de transação ETL, que descreve como um processo extrai dados de um objeto e os transforma em um armazenamento de dados com base em um conjunto de regras. Os usuários definem as funções definidas pelo usuário (UDF) do Pig para ingerir dados de arquivos, fluxos e outras fontes.
O que é ferramenta de porco?
Uma plataforma ou ferramenta conhecida como Pig processa grandes conjuntos de dados. Esta biblioteca contém um alto nível de abstração para processamento de dados no processo MapReduce. Pig Latin é uma linguagem de script de alto nível usada no processo de codificação para desenvolver os códigos de análise de dados.
Qual é a diferença entre Pig e SQL?
SQL Pig Latin e Apache Pig são linguagens procedurais. SQL é uma linguagem de script de natureza declarativa. Depende inteiramente do Apache Pig se o esquema é usado ou não. Os dados podem ser armazenados sem a necessidade de um esquema (os tipos de valor são armazenados em $, $ e assim por diante).
O porco faz parte do Hadoop?
Um aplicativo Pig Hadoop é uma linguagem de programação de alto nível que pode ser usada para analisar grandes conjuntos de dados. O projeto Pig Hadoop do Yahoo! foi um dos primeiros projetos Hadoop . Em geral, ele executa uma quantidade significativa de trabalho de administração de dados ao executar o Hadoop.
No campo da análise de grandes dados, o Pig Hadoop é uma linguagem de programação de alto nível. Para analisar os dados usando o Apache Pig, devemos primeiro escrever scripts usando o Pig Latin. scripts que serão transformados em tarefas MapReduce . Isso é obtido utilizando o Pig Engine, uma extensão do Apache Pig. Seguindo as etapas abaixo, você pode instalar o Apache Pig no Linux/CentOS/Windows (via VM ou Cloudera). O primeiro passo é baixar e instalar o Apache Pig. A segunda etapa é alterar as variáveis de ambiente do Apache Pig usando o arquivo bashrc.
Na etapa 3, determine a versão do Pig . Este arquivo pode ser salvo em outro diretório após ser movido. A quinta etapa é iniciar o Grunt Shell (o script usado para executar o Pig Latin) clicando no comando Pig.
Por que o Pig Latin é a melhor linguagem de script de alto nível para análise de dados
O código de análise de dados Pig Latin é escrito em uma linguagem de script de alto nível. É uma linguagem semelhante ao SQL que se destina a processar fluxos de dados paralelos.
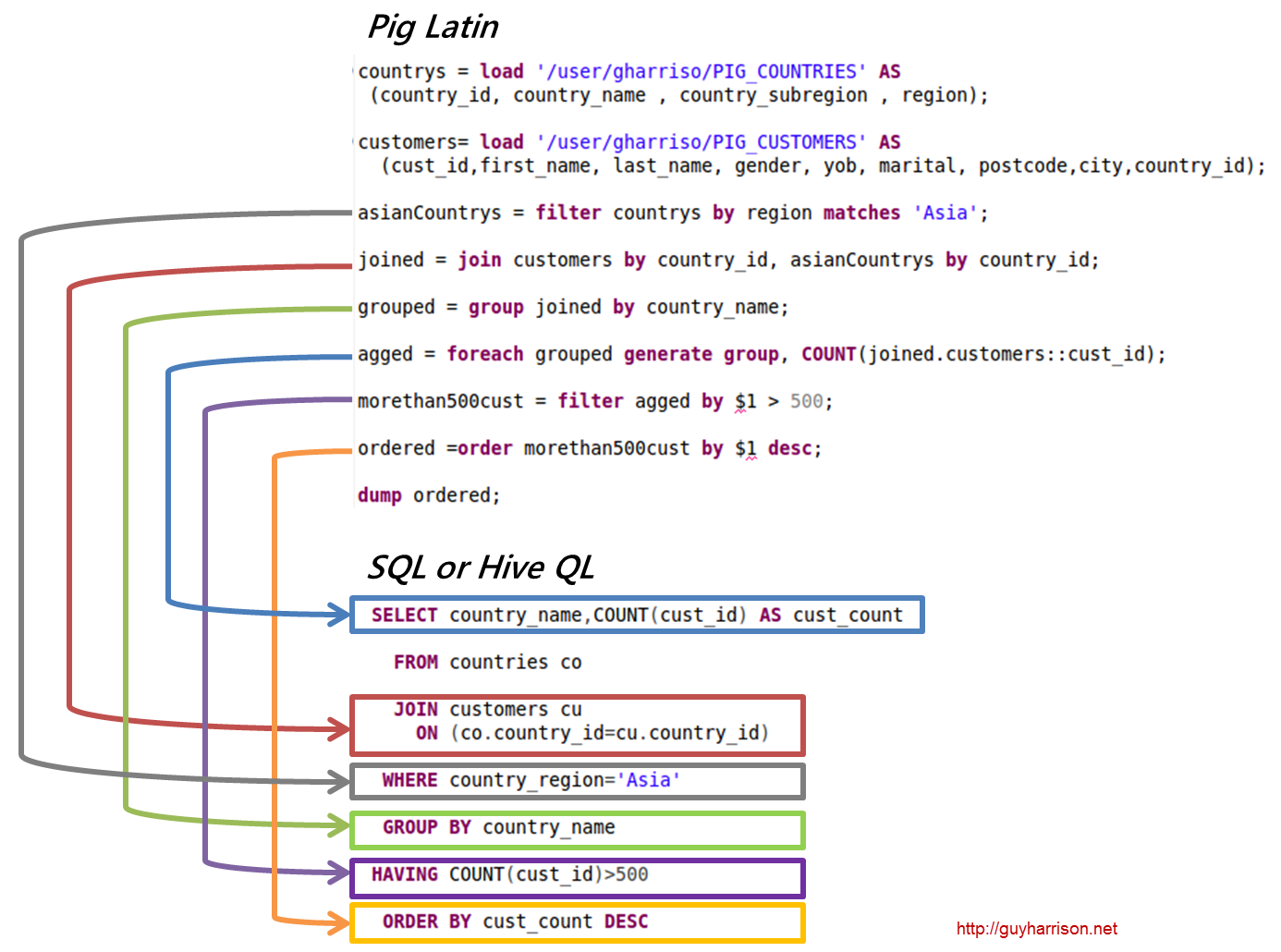
Exemplo de Apache Pig
Pig é uma plataforma de alto nível para criar programas executados no Apache Hadoop. A linguagem para esta plataforma é chamada de Pig Latin. O Pig pode executar seus trabalhos Hadoop em MapReduce, Tez ou Spark. O Pig Latin abstrai a programação do idioma Java MapReduce em uma notação que torna a programação MapReduce mais fácil. Por exemplo, a seguinte instrução Pig Latin é equivalente ao código Java MapReduce acima: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); DUMP A;