
Jak dzielenie może poprawić wydajność bazy danych
Opublikowany: 2022-11-18Sharding to rodzaj partycjonowania bazy danych, który dzieli bardzo duże bazy danych na mniejsze, szybsze i łatwiejsze w zarządzaniu części zwane shardami. Każdy fragment jest własną bazą danych, a każda baza danych może być przechowywana na osobnym serwerze. Sharding jest często używany z bazami danych NoSQL, które zostały zaprojektowane tak, aby były skalowalne i obsługiwały duże ilości danych. Bazy danych NoSQL są często używane w aplikacjach do obsługi dużych zbiorów danych, takich jak media społecznościowe, Internet rzeczy i handel elektroniczny. Dzielenie na części może poprawić wydajność bazy danych poprzez dystrybucję danych i obciążenia na wiele serwerów. Może to pomóc uniknąć wąskich gardeł w bazie danych i zwiększyć skalowalność bazy danych. Istnieje kilka różnych sposobów dzielenia bazy danych na fragmenty. Najbardziej powszechnym podejściem jest użycie strategii dzielenia na fragmenty opartej na kluczach, w której każdy fragment jest odpowiedzialny za zakres kluczy. Innym podejściem jest użycie strategii dzielenia na fragmenty opartej na mieszaniu, w której każdy fragment jest odpowiedzialny za zakres wartości, które są określane przez mieszanie klucza. Bazy danych NoSQL korzystające z fragmentacji mogą być bardziej złożone w zarządzaniu niż tradycyjne relacyjne bazy danych. Administratorzy baz danych muszą znać stosowaną strategię dzielenia na fragmenty i muszą mieć narzędzia do zarządzania i monitorowania fragmentów.
Transakcja ma miejsce między wieloma hostami, gdy dane są rozprowadzane między nimi za pomocą mieszania. Ścinanie to proces dzielenia dużych zestawów danych na mniejsze zestawy danych w instancjach MongoDB.
DynamoDB i Cassandra dzielą dane równomiernie i losowo na fragmenty, aby zapewnić spójne łamanie haszowania . Każdy wiersz w tabeli jest następnie przydzielany do fragmentu, który jest określany przez obliczenie spójnego skrótu wartości kolumn partycji w tym wierszu.
Dzielenie na fragmenty i inne podejścia mogą służyć do dystrybucji danych w klastrach podzielonych na fragmenty w MongoDB. Użycie haszowania.
Co oznacza dzielenie?
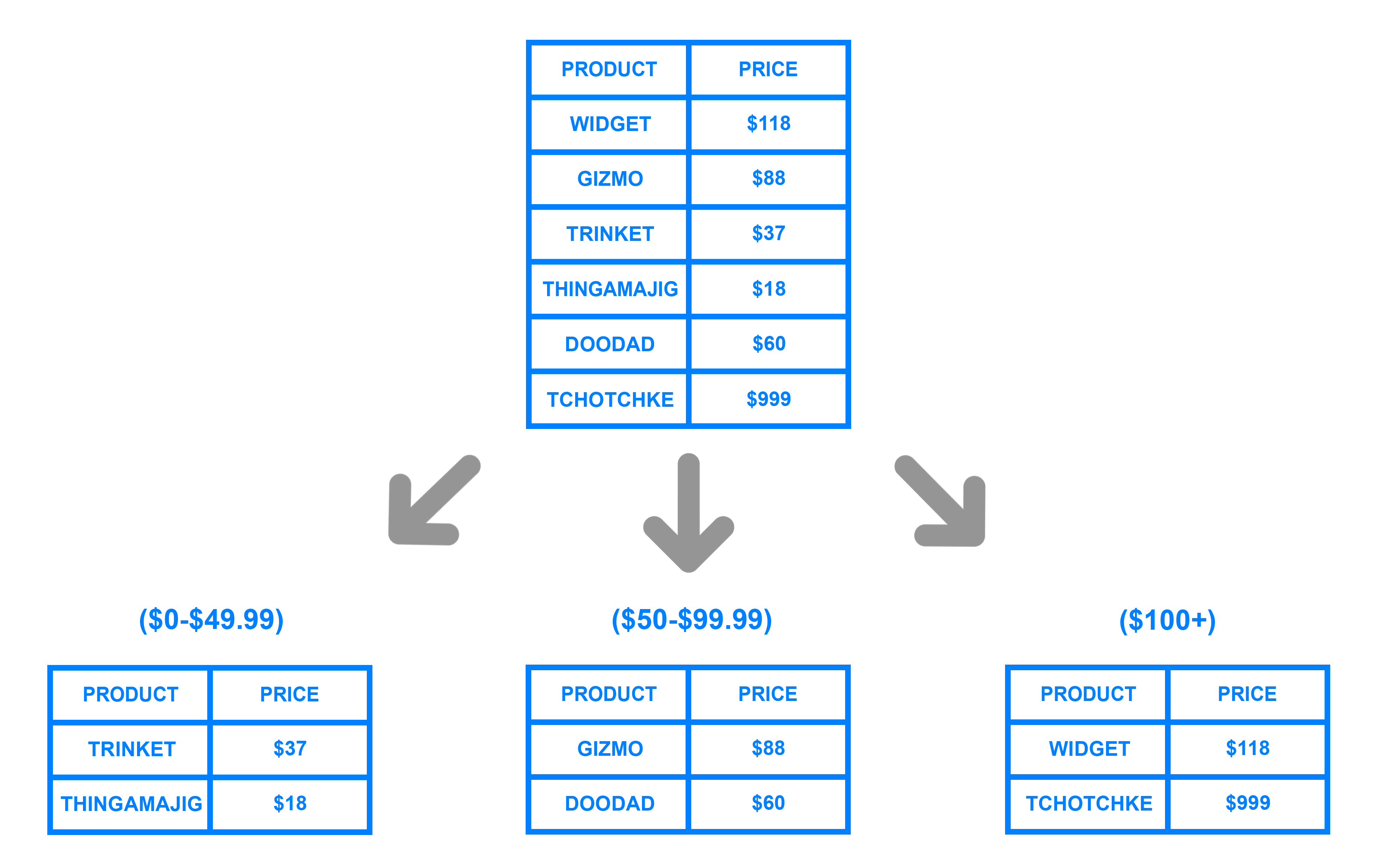
Jest to metoda dystrybucji pojedynczego zestawu danych w wielu bazach danych, a następnie przechowywania go na wielu komputerach. System ma większą pojemność, ponieważ większe zestawy danych można podzielić na mniejsze fragmenty i przechowywać w wielu węzłach danych.
Obciążenie można rozłożyć na wiele węzłów w Sharding, co ułatwia te zadania. Możliwe jest, aby każdy węzeł obsługiwał podzbiór danych i rozdzielał je. Ponadto pozwala to na szybszy wzrost bazy danych przy jednoczesnym zachowaniu łatwości zarządzania.
Bazę danych można również zmniejszyć poprzez sharding. Ponieważ dane są przechowywane w bazach danych, często niemożliwe jest odnalezienie ich wszystkich. Rozmiar bazy danych można zmniejszyć, dzieląc ją na mniejsze części. Dzięki temu dostęp do bazy danych jest łatwiejszy i szybszy.
Dostępnych jest kilka różnych strategii dzielenia na fragmenty. Niektóre strategie pozwalają na dodanie większej liczby węzłów, podczas gdy inne ograniczają liczbę węzłów, które można dodać.
W zależności od potrzeb aplikacji dostępnych będzie kilka opcji. Poniżej przedstawiono kilka typowych strategii.
Jest to prosta metoda dzielenia danych na wiele tabel w różnych węzłach.
Dzielenie danych na mniejsze części za pomocą partycji pionowych to metoda używana do przechowywania danych na różnych poziomach w bazie danych.
Ręczne dzielenie danych na mniejsze części to metoda przechowywania ich w wielu tabelach.
Klaster to metoda organizowania obiektu. Kiedy poziome i pionowe partycje są używane razem, można utworzyć łatwiejszy w zarządzaniu klaster.
Dzielenie na fragmenty z replikacją: Ta strategia łączy dzielenie na fragmenty i możliwość replikacji danych w wielu węzłach.
Łączenie dzielenia na fragmenty i partycjonowania: ta strategia umożliwia dzielenie danych na określone fragmenty danych. Opcje dostępne dla aplikacji będą miały wpływ na jej specyficzne wymagania. Powszechną metodą dzielenia danych na osobne tabele jest użycie partycjonowania poziomego. Podział danych na mniejsze części odbywa się poprzez podzielenie ich na kilka warstw w bazie danych. Partycjonowanie danych na mniejsze części, znane jako partycjonowanie granularne, to metoda przechowywania i pobierania danych w różnych tabelach. Łącząc podziały poziome i pionowe, można stworzyć łatwiejszą do zarządzania strategię klastra. Możliwość replikacji danych z wielu węzłów sprawia, że strategia ta jest tak skuteczna. Zatrzymywanie i partycjonowanie: Ta strategia obejmuje podzielenie obszaru poprzez połączenie dzielenia na fragmenty i danych partycjonowanych.
Co to jest sharding w Blockchain?
W wyniku projektów blockchain duże tabele danych byłyby dzielone na mniejsze fragmenty zwane shardami. Każda partia danych w fragmencie danych na fragmencie danych na fragmencie danych na fragmencie danych na fragmencie danych na fragmencie danych na fragmencie danych na fragmencie danych W przypadku blockchain, zmniejszona opóźnienie i przeciążenie danych można osiągnąć za pomocą shardingu.
Czy Sharding jest odpowiedzią na problemy Bitcoina?
Proces dzielenia łańcucha blokowego na mniejsze, łatwiejsze do zarządzania sekcje, znany jako sharding, ułatwia to. Proces ten pociąga za sobą zwiększenie mocy obliczeniowej sieci i sprawienie, że łańcuch bloków będzie lepiej reagował na żądania użytkowników. Istnieje kilka zalet i wad shardingu. Z jednej strony może zwiększyć wydajność łańcucha bloków, zapewniając jednocześnie bardziej spersonalizowane doświadczenie dla użytkowników. W rezultacie użytkownicy mogą stracić zaufanie, co może prowadzić do fragmentacji łańcucha bloków i utraty łańcucha bloków. Czy Bitcoin kiedykolwiek miał system Sharding ? Chociaż odpowiedź prawdopodobnie brzmi tak, nie ma jednoznacznej rekomendacji. Wydaje się, że sharding jest niezbędnym krokiem w ewolucji łańcucha bloków, aby uczynić go bardziej wydajnym i poprawić jego funkcjonalność. Jednak to społeczność decyduje, czy chce go przyjąć, czy nie.
Co to jest dzielenie modelu?
Partycjonowana sieć neuronowa to graf obliczeniowy, który jest rozłożony na wiele jednostek IPU i oblicza określoną część tego grafu. Model byłby zbudowany na IPU-POD16 DA, który ma na przykład cztery IPU-M2000 i 16 IPU. Jest to zilustrowane na ryc. 1.
Korzyści z dzielenia
Dane mogą być dystrybuowane na wielu serwerach za pomocą Shardingu. Oprócz poprawy wydajności i skali może być przydatny w optymalizacji wydajności. Dane są przechowywane na wielu serwerach w wyniku shardingu. Gdy baza danych otrzymuje więcej żądań w tym samym czasie, jest w stanie obsłużyć je wszystkie. To także dobry sposób na ochronę danych przed hakerami.
Co to jest dzielenie i replikacja w Nosql?

Jakie są różnice między replikacją a shardingiem? Dane z głównego węzła serwera są kopiowane do drugorzędnych węzłów serwera w procesie replikacji. W przypadku awarii serwera może to zwiększyć dostępność danych, działając jednocześnie jako kopia zapasowa. Do wykonania skalowania w poziomie używany jest klucz, który umożliwia skalowanie w poziomie między serwerami.
Technika Sharding to fantastyczny sposób na skalowanie danych. Urządzenie umożliwia skalowanie odczytu i zapisu danych z różnymi prędkościami. Kluczem do sukcesu w shardingu jest wybór dobrego klucza.
Użyj replikacji i dzielenia na fragmenty, aby poprawić wydajność bazy danych
Ponieważ replikacja poprawia wydajność odczytu, można jej używać do dystrybucji danych na wielu serwerach. Do dystrybucji zapisów danych przy użyciu Sharding, bardziej zaawansowanej metody, można użyć wielu serwerów.
Jaki jest cel shardingu?
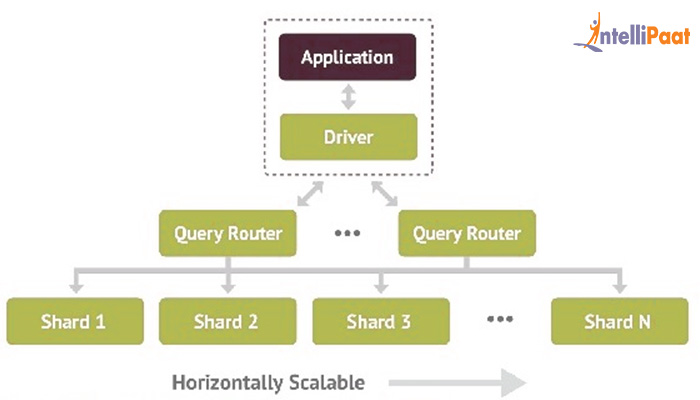
Sharding to proces dzielenia bazy danych na wiele części, z których każda jest przechowywana na osobnym serwerze. Celem shardingu jest poprawa wydajności poprzez rozłożenie obciążenia na wiele serwerów.
Podstawową trudnością związaną z shardingiem jest utrzymanie zrównoważonych shardów i zapewnienie, że każdy z nich przetwarza odpowiednią ilość danych. Dane będą przekrzywione, jeśli odłamki nie będą zrównoważone. Ponadto, jeśli fragmenty nie zostaną rozdzielone, dane będą krzyżować się między fragmentami, co będzie miało wpływ na raportowanie, analizę i pobieranie danych. Jeśli chodzi o dane, kluczem jest możliwość przenoszenia ich między shardami tak szybko i wydajnie, jak to możliwe. Jednak nie zawsze jest to możliwe i tutaj pojawia się problem shardingu. Bardzo ważne jest, aby dane były prawidłowo przetwarzane lub jak najszybciej przenoszone do właściwego fragmentu . Aby rozwiązać te problemy, musisz mieć niezawodny i wydajny mechanizm shardingu.

Dlaczego potrzebujemy shardingu w relacyjnych bazach danych?
Celem dobrze zaprojektowanej architektury bazy danych fragmentów jest zapewnienie równomiernego rozłożenia danych i obciążenia we wszystkich fragmentach bazy danych . Zapytania mogą osiągnąć określony poziom wydajności na każdym z fragmentów.
Korzyści z dzielenia bazy danych
Sharding, metoda poprawiająca wydajność i skalowalność baz danych, to technika, której można użyć. Zbiór danych można podzielić na dyskretne części, a następnie obsłużyć bazę danych w bardziej efektywny sposób za pomocą tej metody. Jest to korzystne dla bazy danych, ponieważ każdy shard może obsłużyć określoną ilość ruchu, zwiększając jego dostępność. W przeciwieństwie do replikacji, która polega na powielaniu zestawu danych, replikacja jest metodą łączenia wielu zestawów danych.
Co to jest Sharding Wyjaśnij na przykładzie?
Każdy wiersz jest przydzielany do innego fragmentu na podstawie własnego klucza w kryptograficznie ważny sposób. Klucz podstawowy zwykle znajduje się w indeksie tabeli lub kluczu podstawowym. Jako przykładu można użyć kolumny ID użytkownika. Możliwe jest jednak wygenerowanie klucza podziału na fragmenty z pola lub z wielu kolumn w tabeli.
Korzyści z dzielenia bazy danych
Duże bazy danych są popularne w przypadku odrzucania wzorców. W ten sposób magazyn danych można podzielić na wiele instancji, zwanych shardami, i dystrybuować w sposób ułatwiający skalowanie.
Łatwiej jest skalować bazę danych, gdy zapytania są wykonywane względem fragmentów, a nie względem głównej bazy danych. Gdy baza danych rośnie lub zmniejsza się, idealnie nadaje się do skalowania fragmentów w dół lub w górę w razie potrzeby.
Ponadto sharding może poprawić wydajność bazy danych. Łatwiej jest pobierać i przetwarzać dane, dzieląc je na mniejsze części. Zwiększa to szybkość reakcji bazy danych, umożliwiając jej łatwiejszą obsługę większego niż przeciętne obciążenia ruchu.
Podstawowym celem shardingu jest zwiększenie wydajności i skali baz danych. Ponieważ jest to wspólny wzór, może być używany do różnych celów.
Czy Sharding można wykonać na Nosql?
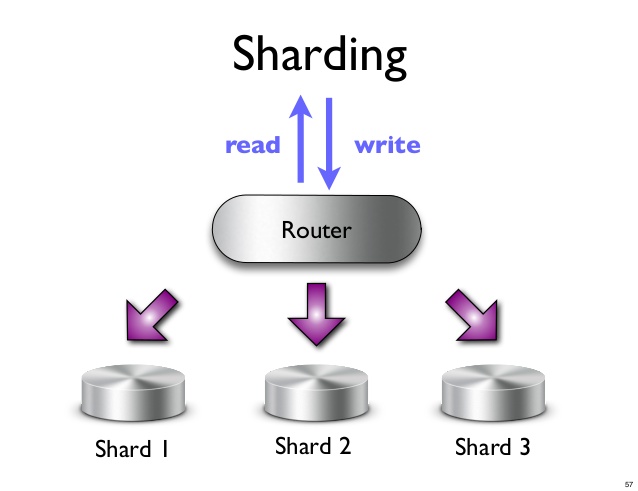
Sharding to technika używana do poziomego podziału danych w bazie danych. Każda partycja nazywana jest fragmentem. Odłamek można dalej podzielić na partycje, z których każda nazywana jest podfragmentem.
Sharding może być używany zarówno z bazami danych SQL, jak i NoSQL. Jest to jednak bardziej powszechne w przypadku baz danych NoSQL, ponieważ są one zazwyczaj bardziej skalowalne niż bazy danych SQL.
Co to jest Sharding w Mongodb
W MongoDB sharding to metoda dystrybucji danych na wielu komputerach. Sharding to poziome partycjonowanie danych w bazie danych lub wyszukiwarce. Każda pojedyncza partycja jest określana jako fragment. Odłamki mogą być przechowywane na jednym serwerze lub rozproszone na wielu serwerach.
Co to jest Sharding w Mongodb?
Jest to metoda dystrybucji danych na wielu komputerach i jest znana jako Sharding. Dzięki MongoDB możemy wspierać wdrożenia z bardzo dużymi zbiorami danych i wysoką przepustowością. System bazy danych z dużą ilością danych lub aplikacja o dużej przepustowości może mieć wpływ na wydajność pojedynczego serwera.
Korzyści z udostępniania danych
Duże zestawy danych wymagają oddzielenia łatwych do zarządzania fragmentów informacji, a to jest nowsza technologia. Dane można podzielić na mniejsze, łatwiejsze do zarządzania części za pomocą shardingu, co pozwala na poprawę wydajności i skali. Sraving jest również przydatny w poprawie bezpieczeństwa danych, ponieważ dzieli dane na bezpieczne strefy.
Jednak partycjonowanie jest bardziej tradycyjną metodą organizacji i nadal jest używane przez wiele firm. Partycja to zbiór podzbiorów danych w instancji bazy danych. Może to również pomóc, jeśli chcesz uporządkować dane w bardziej zorganizowany sposób lub jeśli musisz śledzić liczbę instancji bazy danych, które masz w swoim systemie.
W jaki sposób Sharding poprawia wydajność w Mongodb?
Klucz shard jest używany przez MongoDB do dystrybucji dokumentów z jednej kolekcji do drugiej. Dane są dzielone na porcje w MongoDB, dzieląc rozpiętość kluczowych wartości na nienakładające się zakresy. W rezultacie MongoDB próbuje równomiernie rozmieścić te fragmenty w klastrach.
Czy udostępnianie bazy danych Mongodb jest właściwym posunięciem?
Kiedy należy uruchomić fragment MongoDB?
W gigabajtach nie ma twardej liczby do obliczenia liczby klastrów. Ogólnie jednak najlepiej jest angażować się, gdy baza danych ma więcej niż 200 GB, a procesy tworzenia kopii zapasowych i przywracania mogą zająć trochę czasu.
Która baza danych jest najlepsza do dzielenia?
Metoda ShardingScaling , znana również jako partycjonowanie poziome, jest popularną metodą skalowania w poziomie dla relacyjnych baz danych. Amazon Relational Database Service (Amazon RDS) to zarządzana w chmurze usługa relacyjnej bazy danych z różnorodnymi funkcjami, które sprawiają, że sharding jest tak prosty, jak to tylko możliwe.
Plusy i minusy dzielenia
Używanie fragmentów w celu poprawy wydajności bazy danych to doskonały sposób na osiągnięcie tego celu. Może być w stanie pomóc w zmniejszeniu obciążenia systemu, a jednocześnie pomóc w zwiększeniu wydajności. Ponadto sharding może być szkodliwy dla bezpieczeństwa. Utrata danych w wyniku dzielenia może być poważna i może stanowić zagrożenie dla bezpieczeństwa.
Co to jest dzielenie w Sql
Hierarchia jest tworzona, gdy wiersze i kolumny są oddzielone oddzielnymi bazami danych, które obsługują ruch na poziomie serwera. Odłamek to skrót od tabeli. Niektóre produkty NoSQL, takie jak Apache HBase lub MongoDB, mają sharding, podczas gdy systemy NewSQL zawierają sharding.
Korzyści z dzielenia
Partycjonowanie to proces rozdzielania danych na osobne lub uzupełniające się fragmenty w ramach technologii baz danych . Ta metoda oddzielania od nich danych jest przydatna do dzielenia ich i organizowania w taki sposób, aby można je było przechowywać na różnych komputerach. Istnieje możliwość poprawy wydajności bazy danych poprzez przechowywanie wszystkich danych w osobnych węzłach. Oprócz przesuwania, MySQL umożliwia skalowanie bazy danych w poziomie.
Automatyczne udostępnianie w Nosql
W bazach danych NoSQL auto-sharding to metoda partycjonowania poziomego, w której baza danych jest automatycznie partycjonowana na wielu serwerach. Ma to na celu poprawę skalowalności i wydajności poprzez rozłożenie obciążenia na wiele serwerów. Automatycznego dzielenia na fragmenty można używać z różnymi typami baz danych NoSQL, w tym magazynami klucz-wartość, magazynami dokumentów i kolumnowymi bazami danych.
Dlaczego dzielenie jest ważne dla baz danych Nosql
Bazy danych Nosql, takie jak MongoDB, Cassandra i DynamoDB, można skalować poziomo, dodając więcej serwerów. Ten typ funkcjonalności jest korzystny dla aplikacji, które nie wymagają ścisłych gwarancji spójności lub aplikacji wymagających wysokiego poziomu dostępności.
Jeśli aplikacja wymaga dużej przepustowości, wymagana jest technika dzielenia na fragmenty. W takim przypadku fragmenty bazy danych służą jako narzędzie do tego celu.
Baza danych zawiera fizycznie oddzielne fragmenty zwane fragmentami bazy danych. Systemy te można skalować niezależnie, co oznacza, że mogą obsługiwać dużą przepustowość bez powodowania niespójności. W rezultacie sharding jest ważną funkcją w bazach danych noSQL.
Sharding w Big Data
Co to jest baza danych i jak działa? Zestawy danych są rozdzielane między wiele baz danych, a wiele komputerów może je następnie przechowywać przy użyciu metody shardingu . W rezultacie większe zestawy danych można podzielić na mniejsze fragmenty i przechowywać w wielu klastrach węzłów danych, zwiększając pojemność pamięci masowej.